システム構成要素
目次
応用情報技術者試験(レベル3)シラバス-情報処理技術者試験における知識・技能の細目- Ver. 7.0 に基づき,「システム構成要素」の対策ノートを作成した。
本稿は,システムアーキテクト試験 午前Ⅱ 問題の対策としても活用できるようにしている。
システムの構成
- システムの処理形態,利用形態,適用領域を修得し,応用する。
- 代表的なシステム構成の種類,特徴,システム構成要素間の機能配分を修得し,応用する。
- クライアントサーバシステムの特徴,構成を修得し,応用する。
- システムの信頼性設計の考え方,技術を修得し,応用する。
(1) システムの処理形態・利用形態・適用領域
① 集中処理システム
コスト性能比
保守要員の集中化
② 分散処理システム
分散処理システムを構築する際には、利用者にネットワークの存在を感じさせないように以下のネットワーク透過性を持たせる必要がある。
- アクセス透過性
- 遠隔地の資源にアクセスする際に、同一の方法でアクセスできること
- 移動透過性
- 使用中の資源の位置を移動できること
- 位置透過性
- 遠隔地の資源にアクセスする際に、データの位置を意識せずにアクセスできること
- 規模透過性
- OS やアプリケーションの構成に影響を与えずにシステムの規模を変更できること
- 障害透過性
- システムや資源の一部の障害によりシステム全体の機能が停止し,処理が中断されることがないこと
- 複製透過性
- 資源が複数の位置に複製され配置される場合でも、利用者にはそれらが 1 つの資源として見えること
- 並行透過性
- 複数のプロセスを並行処理できること
③ 利用形態
(2) システム構成
デュアルシステム
デュアルシステム (dual system) とは、機器やシステムの信頼性を高める手法の一つで、同じシステムを二系統用意して、常に両者で同じ処理を行う方式。処理結果を相互に照合・比較することにより高い信頼性を得ることができる。
デュプレックスシステム
デュプレックスシステム (duplex system) とは、機器やシステムの信頼性を高める手法の一つで、同じシステムを二系統用意して、普段は片方を稼働させ、もう片方は待機させておく方式。「アクティブ/スタンバイ構成」とも呼ばれる。
クラスタ
OS,アプリケーション及びハードウェアの障害に対応し,障害時に障害が発生していないサーバに自動的に処理を引き継ぐので,切替え時間の短い安定した運用が求められる場合に有効である。(仮想サーバの冗長化設計における可用性評価)
クラスタシステムのうち、高可用性を実現するものを「HA(High Availability)クラスタ」という。通常、HA クラスタは正常時に稼働を行う主系と障害発生時に処理を引き継ぐ予備系の二重構成をとることで耐障害性を高めている。
フェールオーバは、障害発生時に主系から予備系への引き継ぎを自動的、かつ継ぎ目なしに行う機能で、HA クラスタなどの高信頼性が要求されるシステムに実装されている。
このようなシステムでは主系と予備系の間で「ハートビート」と呼ばれる主系の状態を監視するためのパケットが定期的にやり取りされる。予備系はハートビートの受信が途絶えると主系に障害が発生したと判断し、自律的に主系の処理や設定を引き継ぎ、新たな主系として稼働を始める。このように障害が発生した場合にも利用者に気付かれることなく処理の継続ができることで信頼性が向上する。
タンデム結合
タンデムシステム(tandem system)とは、複数の処理装置やコンピュータを直列につなぎ、それぞれが特定の処理に注力して役割分担する構成のシステム。“tandem” とは馬を前後直列に並べた二頭立て馬車のこと。
マルチプロセッサシステム
マルチプロセッサ(multiprocessor)とは、一台のコンピュータシステムに複数のマイクロプロセッサ(CPU/MPU)を搭載すること。複数のプロセッサで異なるデータや命令を並列に処理することでシステム全体の処理能力を向上させることができる。
ロードシェアリングシステム
ロードシェア(load sharing)とは、情報システムや通信システムの構成法の一つで、同じ機材などを複数用意して、処理を振り分けて負荷を分散する方式。
バックアップサイト
バックアップサイト(backup site)とは、災害などで主要な IT システム拠点での業務の続行が不可能になった際に、緊急の代替拠点として使用する施設や設備のこと。または、Web サイトが停止した場合に備えて用意された、予備の Web サイト。
ホットサイト
ホットサイト (hot site) は,企業の情報システムのバックアップ施設などの運用方式の一つで、遠隔地に設けた施設に本運用とほぼ同じシステムを導入し、常時データ複製などを行いながら稼動状態で待機しておき、障害発生時に直ちに切り替えて運用を引き継ぐ方式。他の方式に比べ最も迅速に切り替え作業を完了できるが、設備などの設営や維持にかかるコストは最も高い。
ウォームサイト
ウォームサイト (warm site) は,企業の情報システムのバックアップ施設などの運用方式の一つで、遠隔地に設けた施設に本運用とほぼ同じシステムを導入し、非稼働状態で待機しておき、障害発生後にシステムを起動して運用を引き継ぐ方式。ホットサイトとコールドサイトの中間的な方式で、引き継ぎにかかる時間やコストも両方式の中間程度となる。
コールドサイト
コールドサイト (cold site) は,企業の情報システムのバックアップ施設などの運用方式の一つで、遠隔地に建物や通信回線など最低限のインフラだけを確保しておき、障害が発生してから必要な機材の搬入や設定作業、バックアップデータの導入などを行なう方式。他の方式に比べ引き継ぎに時間が掛かるが、設備などの設営や維持にかかるコストは安く済む。
仮想化(ホスト型)
ホスト OS で仮想化ソフトウェアを動かし,その上で複数のゲスト OS を稼働させるので,物理サーバへアクセスするにはホスト OS を経由する必要がある。
仮想化(コンテナ型)
アプリケーションの起動に必要なプログラムやライブラリなどをまとめ,ホスト OS で動作させるので,独立性を保ちながら複数のアプリケーションを稼働できる。
VM(Virtual Machine : 仮想マシン)
物理サーバに備わっている機能を利用するので,ハードウェアの障害にだけ対応し,障害時に業務停止が許容される場合に有効である。
ライブマイグレーション
ライブマイグレーション(Live Migration)は、ある物理サーバ上で稼働している仮想マシンを、OS やソフトウェアを停止させることなく別の物理サーバに移し替え、処理を継続させる技術である。切り替えによるダウンタイムはほとんどゼロで、移動前の処理やセッションが全て引き継がれるため可用性を損なうことがない。
仮想サーバを停止させずに物理サーバ間で仮想サーバを移動することが可能となるので,メンテナンスなど業務移行の際も含めて業務の停止が全く許容できない場合に有効である。
パーテショニング
物理サーバのリソース(CPU,メモリなど)をブロック単位に物理的に分割し,あるブロックの障害が他のブロックに影響しないようにするので,障害時に業務の停止が許容できない場合に有効である。
(3) ハイパフォーマンスコンピューティング
HPC(High Performance Computing : ハイパフォーマンスコンピューティング)は,高精度な高速演算を必要とする分野で利用される。
大規模並列
アレイプロセッサ
アレイプロセッサ (array processor) とは、多数のデータに同時に同じ演算を行うベクトル処理に適した設計のマイクロプロセッサおよびコンピュータ。1990 年代までのスーパーコンピュータに多く見られた設計様式である。
(4) クライアントサーバシステム
クライアントサーバシステムとは、通信ネットワークを利用したコンピュータシステムの形態の一つで、機能や情報を提供する「サーバ」(server)と、利用者が操作する「クライアント」(client)をネットワークで結び、クライアントからの要求にサーバが応答する形で処理を進める方式。
クライアントサーバシステムは,分散処理形態の代表的なシステムである。このシステムでは,サーバを要求するクライアントと,サービスを提供するサーバから構成される。
クライアントサーバシステムの特徴
クライアントサーバシステム(CS : Client Server System)は,サービス(システムの処理機能)を行うサーバと,サーバに対してサービスを要求するクライアントからなる。

サーバはサービスを提供するプログラムを単位とする。よって,1 台の物理的なコンピュータ上で複数のサーバ(サービス)を稼働することが可能である。
サーバが提供する代表的な機能は下表に示す種類がある。各機能は独立しているため,サーバ単位での拡張や機能追加が可能である。
| サービス | 内容 |
|---|---|
| ファイルサーバ | ファイルの共有機能を提供する |
| プリントサーバ | 1 台のプリンタを複数のクライアントで共有し,印刷要求を制御して印刷を行う |
| データベースサーバ | データベースの管理,アクセス制御を行う |
| コミュニケーションサーバ | 外部との通信機能を提供する |
| メールサーバ | 電子メールの配信機能を提供する |
NAS (Network Attached Storage)
TCP/IP のコンピュータネットワークに直接接続して使用するファイルサーバである。
ファイルサービス専用のコンピュータであり、専用化や用途に合うようにチューニングされた OS などにより、高速なファイルサービスと容易な管理機能が実現されている。
シンククライアント
シンクライアントは、ユーザが使用する端末にデータやアプリケーションを持たせず、サーバに接続するための必要最小限のネットワーク機能や入出力用の GUI だけを装備させ、サーバ側で必要なデータ処理をするものを指す。シン(Thin)とは「薄い、少ない」の意味である。
シンクライアントシステムには、リモートアクセス型、ネットワーク型、画面転送型など様々な方式があるが、いずれも端末にデータやアプリケーションを持たせないため、情報漏えいに対するセキュリティ対策になるほか、ファイルのバックアップ、OS やアプリケーションプログラムのアップデート(セキュリティホール対策版への更新)、ウィルススキャン、暗号化など、日常の運用をサーバ側で集中管理できる利点がある。
3 層クライアントサーバシステム
3 層クライアントサーバシステムは,現在のデータベースを主体する業務アプリケーションシステム機能を 3 階層で構成したものである。プレゼンテーション層ではユーザインタフェースを提供,ファンクション層(アプリケーション層)ではデータ処理条件の組立て,データの加工,データベース層ではデータベースを管理する機能である。
プレゼンテーション層,ファンクション層,データ層に分離したアーキテクチャであり,各層の OS は異なってもよい。

| 側 | 層 | 役割 | サーバなど |
|---|---|---|---|
| クライアント側 | プレゼンテーション層 | 入力の受付(検索条件の入力),結果の表示 | Web ブラウザなど |
| サーバ側 | ファンクション層※ | 入力から問合せを生成(データ処理条件の組立て),結果から結果画面を生成(データ加工) | アプリケーションサーバ |
| データ層 | DB へアクセス(データへのアクセス),結果を出力 | データベースサーバ |
- ※ ファンクション層は,アプリケーション層,トランザクション層,ビジネスロジック層の名称でも呼ばれることがある。
演習問題
3 層クライアントサーバシステムの各層の役割のうち,適切なものはどれか。
- データベースアクセス層は,データを加工してプレゼンテーション層に返信する。
- ファンクション層は,データベースアクセス層で組み立てられた SQL 文を解釈する。
- ファンクション層は,データを加工してプレゼンテーション層に返信する。
- プレゼンテーション層は,データベースアクセス層に SQL 文で問い合わせる。
正解は,3. である。
(5) Web システム
Web ブラウザ
Web クライアントのうち、受信したページの内容を整形して画面に表示し、人間が閲覧するために用いるものを特に「Web ブラウザ」(web browser : ウェブブラウザ)という。
Web サーバ
Web サーバは、ブラウザと DB サーバの間にたち、ブラウザから受け取ったリクエストを基に組み立てた SQL 文で DB サーバに問合せを行い、DB から返された結果を HTML 文書に加工してブラウザに返す役割をもっている。
データベース(DB)へのアクセスを行うブラウザからのリクエスト処理を,Web サーバが受信し解読した後に行う一連の実行処理の順序を以下に示す。ここで,Web サーバはリクエスト処理ごとに DB への接続と切断を行うものとする。
- DB への接続
- SQL 文の組立て
- DB へのアクセス
- HTML 文書の組立て
- ブラウザへの送信
- DB の切断
(6) RAID
RAID(Redundant Arrays of Inexpensive Disks)とは、ハードディスクなどのストレージ(外部記憶装置)を複数台まとめて一台の装置として管理する技術。1987 年カリフォルニア大学バークリー校のデービッド・パターソン(David A.Patterson)氏、ガース・ギブソン(Garth Gibson)氏、ランディ・カッツ(Randy Katz)氏の 3 人によって提唱された。
次表のように,RAID には 0~5 のレベルがあるが、その区別は本来のデータとエラー訂正用のデータ(ハミング符号・パリティビット)を、どのように書き込むかによって定義されている。
| 種類 | 説明 |
|---|---|
| RAID0 | RAID 0 とは、複数のストレージ(外部記憶装置)をまとめて一台の装置のように管理する RAID 技術の方式(RAID レベル)の一つで、複数の装置に均等にデータを振り分け、並行して同時に記録することで読み書きを高速化する方式。ストライピング(striping)ともいう。 |
| RAID1 | RAID 1 とは、複数のストレージ(外部記憶装置)をまとめて一台の装置のように管理する RAID 技術の方式(RAID レベル)の一つで、2 台の装置にまったく同じデータを同時に書き込む方式。ミラーリング(mirroring)ともいう。 |
| RAID2 | RAID 2 とは、複数の外部記憶装置(ハードディスクなど)をまとめて一台の装置として管理する RAID 技術の方式の一つで、ハミングコードと呼ばれる誤り訂正符号を生成し、データとは別に分散して記録する方式。効率の悪さなどからほぼ使われていない。 |
| RAID3 | RAID 3 とは、複数の外部記憶装置(ハードディスクなど)をまとめて一台の装置として管理する RAID 技術の方式の一つで、1 台をパリティと呼ばれる誤り訂正符号の記録に割り当て、残りの装置にビット単位やバイト単位でデータを分散記録する方式。 |
| RAID4 | RAID 4 とは、複数の外部記憶装置(ハードディスクなど)をまとめて一台の装置として管理する RAID 技術の方式の一つで、1 台をパリティと呼ばれる誤り訂正符号の記録に割り当て、残りの装置にブロック単位でデータを分散記録する方式。 |
| RAID5 | RAID 5 とは、複数の外部記憶装置(ハードディスクなど)をまとめて一台の装置として管理する RAID 技術の方式の一つで、書き込むデータから誤り訂正符号を生成し、データとともに分散して記録する方式。 |
| RAID6 | RAID 6 とは、複数の外部記憶装置(ハードディスクなど)をまとめて一台の装置として管理する RAID 技術の方式の一つで、データからパリティと呼ばれる誤り訂正符号を 2 つ生成し、データとともに分散して書き込む方式。 |
ストライピング
ストライピング (striping) とは,複数のストレージ装置(ハードディスクなど)をまとめて一台の装置のように管理する RAID 技術の方式(RAID レベル)の一つで、複数の装置に均等にデータを振り分け、並行して同時に記録することで読み書きを高速化する方式。RAID 0 のこと。
ミラーリング
ミラーリング(mirroring)とは、「鏡写し」という意味の英単語で、IT 分野では同じ内容を同時に二ヶ所に反映することを指す。複数の表示機器に同じ内容を同時に映し出すことや、複数の記憶装置に同じデータを同時に記録することなどを表す。
(7) 信頼性設計
フォールトアボイダンス(fault avoidance)
フォールトアボイダンスは,システム構成要素の個々の品質を高めて故障が発生しないようにする概念である。具体的には,信頼性の高い機器でシステムを構成し,機器の定期保守などによって,障害の発生を防ぐ。
フォールトトレランス
フォールトトレランスとは,システムが部分的に故障しても,システム全体としては必要な機能を維持するシステムである。障害が発生した場合,一部の機能を止めてでもシステムを稼働させ続けることを目的に,機器を冗長にしてシステムの停止を回避する。フォールトトレランスには,次表に示す概念がある。
| 名称 | 内容 |
|---|---|
| フェイルセーフ | フェイルセーフ(fail safe)とは、機器やシステムの設計などについての考え方の一つで、部品の故障や破損、操作ミス、誤作動などが発生した際に、なるべく安全な状態に移行するような仕組みにしておくこと。 |
| フェイルソフト | フェイルソフト(fail soft)とは、機器やシステムの設計などについての考え方の一つで、事故や故障が発生した際に、問題の個所を切り離すなどして被害の拡大を防ぎ、全体を止めることなく残りの部分で運転を継続すること。 |
| フェイルオーバー | フェイルオーバー(failover)とは、稼働中のシステムに障害が発生した際に、代替システムがその機能を自動的に引き継ぎ、処理を続行する仕組み。業務用の情報システムなどで、機器やネットワークの信頼性を高めるためによく用いられる。 |
| フールプルーフ | フールプルーフ(foolproof)とは、機器の設計などについての考え方の一つで、利用者が操作や取り扱い方を誤っても危険が生じない、あるいは、そもそも誤った操作や危険な使い方ができないような構造や仕掛けを設計段階で組み込むこと。また、そのような仕組みや構造。 インタロックの例として,動作中の機械から一定の範囲内に人間が立ち入ったことをセンサが感知したとき,機械の動作を停止させる仕組みがある。 |
| フォールトマスキング | 故障が発生したときに,あらかじめ指定されている縮小した範囲のサービスを提供すること。 |
フォールトトレラントシステムの実現方法として,システムを 1 台のコンピュータではなく,複数台のコンピュータで多重化する。
システムの評価指標
- システムの性能,信頼性,経済性を測るための考え方,評価指標,それらを高める設計の考え方を修得し,応用する。
(1) システムの性能特性と評価
① システムの性能評価
レスポンスタイム(応答時間)
レスポンスタイム(応答時間)は,システムへデータを入力し終えてから,最初の反応が返ってくるまでの時間である。レスポンスタイムは,CPU が処理を行っている時間(CPU 時間),他の処理で専有された入出力装置や CPU などが使用できるようになるまでの待ち時間(処理待ち時間)の合計になる。
ターンアラウンドタイムは,コンピュータに対して処理の依頼(ジョブの投入)を行ってから,処理結果の出力が完了するまでの時間である。
レスポンスタイムとターンアラウンドタイムの関係を下図に示す。なお,オーバヘッドとは,本来の処理とは別に余分にかかる作業のことである。

シングルジョブで動作するコンピュータシステムでは,平均ターンアラウンドタイム $A$ とスループット $T$ の積は 1 になる。
\[ A \times T \approx 1 \]ベンチマーク
システムの性能を評価するために,ベンチマーク(比較のための指標の意味)テストというプログラムを実行して性能を評価する。代表的なベンチマークテストを下表に示す。
| 種類 | 説明 |
|---|---|
| SPEC | ベンチマークテストの策定を目的とする非営利団体 SPEC が策定したベンチマーク。整数演算性能を測定する SPECint,浮動小数点数演算を測定する SPECfp がある。 |
| TPC | 非営利団体 TPC が策定したオンライントランザクション処理の性能評価用のベンチマークテスト。TPC-C,TPC-E(TPC-C の後継)がある |
| 命令ミックス | CPU の性能評価に使用。プログラム中で頻繁に使用される命令の出現頻度から 1 命令当たりの平均命令実行時間を設定し,CPU の処理速度を算出する。 |
SPECint, SPECfp
SPEC(Standard Performance Evaluation Corporation)とは、コンピュータシステムを実際の使用環境に近い状態で性能測定する標準的な手法を策定し、測定結果を登録・公表する国際的な非営利団体。1988 年に大手コンピュータメーカーなどを中心に設立された。
著名なベンチマークには、CPU(マイクロプロセッサ)の整数演算性能を計測する「SPECint」シリーズや、浮動小数点演算性能を計測する「SPECfp」シリーズなどがある。現在ではこれらを合わせて「SPEC CPU」シリーズとなっている。
② キャパシティプランニング
キャパシティプランニングとは、情報システムの設計段階で現状の最大負荷だけでなく、将来予測される最大負荷時にもサービスの水準を維持できるような設計を検討することである。検討対象には、CPU の性能や回線の速度などに加えて経済性や拡張性も含まれる。
キャパシティプランニングを行うことで適切なハードウェアを選定し、最適な投資を行うことができる。
稼働状況が継続的に監視されているシステムがある。稼働して数年後に新規業務をシステムに適用する場合に実施する,キャパシティプランニングの作業項目の順序は次のとおり。
- システムの稼働状況から,ハードウェアの性能情報やシステム固有の環境を把握する。
- 利用者などに新規事業をヒアリングし,想定される処理件数や処理に要する時間といったシステムに求められる要件を把握する。
- システム特性に合わせて,サーバの台数,並列分散処理の実施の有無など,必要なシステム構成の案を検討する。
- システム構成の案について,適正なものかどうかを評価し,必要があれば見直しを行う。
スケールアウト
接続されるサーバの台数を増やすことでサーバシステム全体としての処理能力や可用性を向上させる。同等の性能アップであればスケールアップよりも低コストであることが多い。
例えば,参照系のトランザクションが多いので,複数のサーバで分散処理を行っているシステムはスケールアウトが適している。
スケールアップ
サーバを構成する各処理装置をより性能の高いものに交換したり、プロセッサの数などを増やすことでサーバ当たりの処理能力を向上させる。追加・削除・更新処理が頻繁に発生するなど、並列実行による負荷分散が困難なシステムに適している。
スケールアップの例は,以下のとおり。
- サーバのCPUを高性能なものに交換することによって,サーバ当たりの処理能力を向上させる
- サーバのディスクを増設して冗長化することによって,サーバ当たりの信頼性を向上させる
- サーバのメモリを増設することによって,単位時間当たりの処理能力を向上させる
スケールイン
システムを構成する物理サーバの台数を減らすことによって,システムとしてのリソースを最適化し,無駄なコストを削減する。
(2) システムの信頼性特性と評価
① RASIS
RASIS(Reliability Availability Serviceability Integrity Security)とは、コンピュータシステムが期待された機能・性能を安定して発揮できるか否かを示すのに用いられる代表的な5つの特性の頭文字を繋ぎ合わせた用語。
| 特性 | 説明 |
|---|---|
| 信頼性(Reliability) | 障害や不具合による停止や性能低下の発生しにくさを表す。稼働時間当たりの障害発生回数(MTBF:Mean Time Between Failures)などの指標で表すことが多い。 |
| 可用性(Availability) | 稼働率の高さ、障害や保守による停止時間の短さを意味する。稼働が期待される時間に対する実際の稼働時間の割合(稼働率)などの指標で表す場合が多い。 |
| 保守性(Serviceability) | 障害復旧やメンテナンスのしやすさを表す。障害発生から復旧までの平均時間(MTTR:Mean Time To Repair)などの指標で表すことが多い。 |
| 保全性(Integrity) | 過負荷や障害、誤操作などによるデータの破壊や喪失、不整合などの起こりにくさを意味する。 |
| 機密性(Security) | 外部の攻撃者による不正侵入や遠隔操作、データやプログラムの改竄や機密データの漏洩などの起こりにくさを表す。 |
② 信頼性指標と信頼性計算
MTBF(Mean Time Between Failures : 平均故障間隔)とは、機器やシステムなどの信頼性を表す指標の一つで、稼働を開始(あるいは修理後に再開)してから次に故障するまでの平均稼働時間。「MTBF が 10 年」とは「10 年の稼働時間の間に平均 1 回故障する」という意味。
MTTR(Mean Time To Repair : 平均復旧時間)とは、機器やシステムなどの信頼性を表す指標の一つで、故障などで停止した際に、復旧にかかる時間の平均。「MTTR が 10 時間」とは「修理に平均 10 時間かかる」という意味。
稼働率と MTBF,MTTR には,次式の関係がある。
上式より,MTBF と MTTR は,稼働率が 0.5 のときに等しくなる。
エラーログ取得機能は,MTBF を長くするよりも,MTTR を短くするのに役立つ。
バスタブ曲線(bathtub curve)とは,故障率が時間の伴って減少,一定,増加の順になっている曲線で,非修理系アイテムの故障曲線として用いられる。
バスタブ曲線の初期故障期間の対策として,設計や製造のミスを減らすために,設計審査や故障解析を強化する。
バスタブ曲線の偶発故障期間は,故障率がほぼ一定とみなせる期間であり,アイテムの通常の使用期間に相当する。この期間の長さは,一般に,耐用寿命といわれる。
バスタブ曲線の磨耗故障期間は,アイテムの老朽化による故障が多く発生する期間である。そのため,この期間においては予防保全によるアイテムの取替えが効果的である。
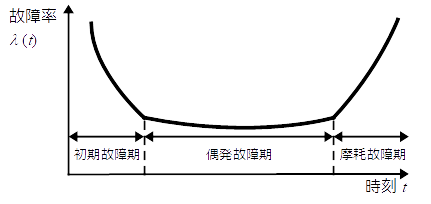
ちなみに,縦軸に故障率,横軸に時間を取ったときの形状が西洋の浴槽の断面に似ているのでこのように呼ばれている。船底形曲線ともいう。
(3) システムの経済性の評価
本稿の参考文献
- 目指せ!電気通信主任技術者 線路設備及び設備管理 対策ノート「設備管理の概要」
- 電気通信主任技術者総合情報「電気通信主任技術者試験用 設備管理 信頼性計算攻略メモ」