サービスマネジメント
目次
応用情報技術者試験(レベル3)シラバス-情報処理技術者試験における知識・技能の細目- Ver. 7.0 に基づき,「サービスマネジメント」の対策ノートを作成した。
本稿は,プロジェクトマネージャ試験 午後Ⅱ の対策としても活用できるようにしている。
サービスマネジメント
- サービスマネジメントの目的,考え方を修得し,適用する。
- サービスマネジメントシステムの確立,実施,維持及び継続的改善の考え方を修得し,適用する。
(1) サービスマネジメントの目的と考え方
サービス
サービスマネジメントにおけるサービスは,以下のとおり定義することができる。
ヒト,モノ,システムなどの要素を組み合わせ,顧客に価値を提供する活動
(出典)「ITIL 入門 IT サービスマネジメントの仕組みと活用」
顧客が特定のコストやリスクを負わずに達成することを望む成果を促進することによって,顧客に価値を提供する手段
(出典)「ITIL 用語および頭字語集」
上記のサービスを概念図で示す。

サービスが異なれば,その特徴も異なるが,おおよそ全てのサービスに共通する代表的な 4 つの特徴を示す。
| 無形性 | 形がなく,触ることや試すことができない |
|---|---|
| 生産と消費の同時性 | サービスの提供と消費が同時進行するため,サービス消費者がサービス提供プロセスに深く関与することになる |
| 不均一性 | サービス提供の都度,サービスの品質がバラツキやすい |
| 消滅性 | 作りおきができない ※生産と消費の同時性から生じる特徴 |
サービスの設計内容は,選択する供給モデルによって大きく左右される。
- インソーシング
- サービスの供給に外部委託を行わず,組織内部のリソースだけを活用するモデル
- アウトソーシング
- サービスの供給に外部のリソースを活用するモデル
- コソーシング
- 複数のアウトソーシング組織と連携してサービスを供給するモデル
- パートナシップ(またはマルチソーシング)
- 複数のアウトソーシング組織と連携してサービスを供給するのはコソーシングと同じであるが,市場の拡大や変化への戦略的な対応が含まれる。
- アプリケーションサービス供給
- アプリケーションサービスプロバイダ(ASP)からアプリケーション機能の供給を受けるサービス供給モデル
- ビジネスプロセスアウトソーシング (BPO : Business Process Outsourcing)
- コールセンタ業務を委託するなど,組織のある業務機能の全体を外部委託するサービス供給モデル。専門のビジネススキルを低コストで利用できるが,自社の事業上のナレッジの蓄積にはならない。
- ナレッジプロセスアウトソーシング (KPO : Knowledge Process Outsourcing)
- BOP の進化形であり,外部組織からのビジネスプロセスだけでなく,高度な専門知識(ナレッジ)の供給を受けるサービスモデルである。
サービスコンポーネント
サービス品質
サービスマネジメント
情報システムの運用や保守は,ハードウェアやソフトウェアなどの技術的な側面と顧客の要求を満たすためのサービスとしての側面から対応する必要がある。サービスマネジメントとは,高品質なサービスを顧客に提供するためのものである。ITIL では,この目的を実現するための指針を成功事例に基づいてまとめている。
サービスマネジメントを導入する目的と効果を以下に示す。
- 現在および将来のビジネスニーズに即した,最適な IT サービスを提供することで,ビジネスを下支えし,その成果を最大化する
- IT サービス提供に関わるプロセスやルール・方針を標準化することで,サービスの品質の向上および中長期的なコスト削減を実現する
- IT サービスの品質を定量的に把握・管理することで,サービスの品質や費用対効果の継続的な改善力を醸成する
- ビジネスに対する IT サービスの貢献を明確化することで,IT サービス提供部門にプロフェッショナル意識を醸成する
- IT サービスの特徴・内容や制約事項などをユーザに正しく理解してもらうことで,IT サービスに対する価値観を共有する
サービスライフサイクルの段階(計画立案,設計,移行,提供,改善)
サービルライフサイクルの段階(計画立案,設計,移行,提供,改善)を次表に示す。
| 段階 | 内容 |
|---|---|
| サービス戦略(サービスストラテジ) | IT サービスおよび IT サービスマネジメントに対する全体的な戦略を確立する。このプロセスに含まれる戦略レベルのプロセスは,サービスポートフォリオ管理,財務管理である。 |
| サービス設計(サービスデザイン) | 事業要件を取り入れ,事業が求める品質,信頼性及び柔軟性に応えるサービスと,それを支えるプラクティス及び管理ツールを作り出す。 |
| サービス移行(サービストランジション) | サービスおよびサービス変更を運用に利用できるようにするために,前の段階の成果を受け取り,事業のニーズを満たすかどうかをテストし,本番環境に展開する。 |
| サービス運用(サービスオペレーション) | 顧客とサービス提供者にとって価値を確保できるように,IT サービスを効果的かつ効率的に提供しサポートする。 |
| 継続的サービス改善 | IT サービスマネジメントプロセスと IT サービスに対する改善の管理を責務とし,効率性,有効性及び費用対効果を向上させるために,サービス提供者のパフォーマンスを継続的に測定して,プロセス,IT サービス,インフラストラクチャに改善を加える。 |
- サービスストラテジ (SS : Service Strategy)
- サービスストラテジでは,今後サービスマネジメントに取り組む企業が,どのようにサービスを設計・開発し,実装していくべきかといった,サービス戦略を策定する際に必要となるガイダンスを記述している。
- サービスデザイン (SD : Service Design)
- サービスデザインでは,現在および将来のビジネス要件を満たすためのサービス内容とサービスマネジメントプロセスの設計・開発に向けたガイダンスを記述している。
- サービストランジション (ST : Service Transition)
- サービストランジションでは,新規サービスまたは既存サービスの変更を,確実かつ円滑に本番環境に移行・導入するためのガイダンスを記述している。
- サービスオペレーション (SO : Service Operation)
- サービスオペレーションでは,日常的な IT サービスの提供を効果的・効率的に実装するためのガイダンスを記述している。
- 継続的なサービス改善 (CSI : Continual Service Improvement)
- 継続的なサービス改善では,サービスの設計・導入・オペレーションを通じて,顧客にとってより良い価値を創造および維持して行くためのガイダンスを記述している。
サービストランジションの目標を以下に示す。
- 新規または変更された IT サービスを適切に計画・管理し,期待したコスト・品質・期間内で,確実に本番環境に移行する
- 新規または変更された IT サービス,コミュニケーション,ドキュメント,トレーニング,ナレッジの引き継ぎなどを通じて,顧客,ビジネス部門などの満足度を高める
- IT サービスや,それを支えるアプリケーション,技術的なソリューションの適切な利用を促進する
- 顧客のビジネス革新プロジェクトと整合した,明確なサービストランジション計画を示す
(2) サービスマネジメントシステムの確立,実施,維持及び継続的改善
サービスマネジメントシステム
ITIL では,サービスマネジメントを「顧客に対し,サービスの形で価値を提供する組織の専門能力の集まり」として定義している。
システムの運用や保守などを IT サービスとしてとらえて体系化し,適切なサービス品質で,サービス価値を提供する。また,顧客満足度を考え,サービス提供者だけでなく,ユーザの順守事項も決定する。
IT サービスマネジメントを導入する際の手順は以下のとおり。
- ビジョンの明確化
- 現状の把握
- 目標の設定
- 目標達成方法の検討
- 目標達成状況の把握方法の検討
- 継続的改善方法の検討
サービスの要求事項
顧客
サービス提供者
サービスオーナは,特定の IT サービスの提供に対する責任をもつとともに,顧客も含めた関係者に対する説明責任をもつ。
JIS Q 20000 の規格群(ISO/IEC 20000 シリーズ)
ITIL は,サービスマネジメントを実現するためのガイドラインである。これを日本工業規格(JIS)が日本における IT サービスマネジメントの実践的な規格・ルールとして定めたものが JIS Q 20000(JIS Q 20000-1 : 第1部 : サービスマネジメントシステム要求事項,JIS Q 20000-2 : 第2部 : 実践のための規範)である。
JIS Q 2000-1 : 2012 0.2 サービスマネジメントシステム要求事項
この規格の要求事項は,サービスの要求事項を満たし,かつ,顧客及びサービス提供者の双方に価値を提供する,サービスの設計,移行,提供及び改善を含む。この規格は,サービス提供者がサービスマネジメントシステム(以下,SMS という。)を計画,確立,導入,運用,監視,レビュー,維持及び改善する場合の統合されたプロセスアプローチを要求する。
JIS Q 20000-1:2012(サービスマネジメントシステム要求事項)の "サービスマネジメントシステムの監視及びレビュー" の要求事項の一つに「監査員は,自らの仕事を監査してはならない」がある。
JIS Q 20000-1:2020(サービスマネジメントシステム要求事項) 9 パフォーマンス評価 9.2 内部監査 9.2.1 では,次のように定められている。
組織は,SMSが次の状況にあるか否かに関する情報を提供するために,あらかじめ定めた間隔で内部監査を実施しなければならない。
a) 次の事項に適合している。
- SMSに関して,組織自体が規定した要求事項
- この規格の要求事項
b) 効果的に実施され,維持されている。
(3) ITIL
ITIL (Information Technology Infrastructure Library)
ITIL は,1989 年に英国が発行した IT サービスマネジメント(ITSM)のガイドラインである。IT サービスに関する国際的な教本として各国で利用されており,最新版は 2019 年に ITIL4 が発行されている。
サービスマネジメントの成功事例(ベストプラクティス[1])を英国政府機関の OGC(Office of Government Commerce)が体系化したもので,世界的な標準企画として扱われている。サービスマネジメントは,情報システムの運用や保守などを行う IT サービスの事業者が顧客の要求を満たすために自社のサービスを管理するための取組み(フレームワーク)のことである。
ITIL 2011 edition いよれば,サービス・パッケージは,コアサービス,実現サービス及び強化サービスの組合せで構成された,特定の種類の顧客ニーズへのソリューションを提供する複数のサービスの集まりである,と説明されている。
ITIL が定義する機能の名称には,サービスデスク,技術管理,アプリケーション管理,IT 運用管理の 4 つがある。
ITIL で定義されるサービスのライフサイクルにおける,サービストランジション段階では,規定された要件と制約に沿って,サービスを運用に移行し,確実に稼働させる。
7 ステップの改善プロセス
ITIL 2011 edition に記載されている 7 ステップの改善プロセスとは,改善を ① 特定,② 定義,③ 収集,④ 処理,⑤ 分析,⑥ 提示,⑦ 実装するために必要な手順を定義および管理するプロセスのことである。
- 改善の戦略を識別する
- 測定するものを定義する
- データを収集する
- データを処理する
- 情報とデータを分析する
- 情報を提示して利用する
- 改善を実施する

"測定するものを定義する" 活動では,効果的にサービスを測定するために,経済的,定量的で,求められる結果を出すために役立つ,重要で意味のある少数の指標に着目して測定項目を定義する。
ITIL の IT サービス継続性管理の達成目標として,災害が起こった後,一定期間内にシステムを復旧し事業を継続させることが挙げられる。
ITIL によれば,既存及び新規の全てのサービスに対してビジネスインパクト分析を行うことを役割とするマネージャは,IT サービス継続管理プロセス・マネージャである。
ITIL では,リスクの管理アプローチとして,Risk IT フレームワーク,M_o_R,ISO31000,ISO/IEC27001 を取り上げている。
Risk IT フレームワーク
Risk IT フレームワークとは,ISACA(情報システムコントロール協会)が策定した IT に関わるリスクの効果的なガバナンスや管理のためのフレームワークである。
Risk IT フレームワークでは,"リスクガバナンス","リスク評価","リスク対応" の三つの領域の中に,それぞれ三つずつの主要なプロセスが提示されている。"リスクガバナンス" において企業にリスク管理の仕組みを確立し,"リスク対応" において事業の優先度に基づいて費用対効果の高い方法でリスクが対処される仕組みを確立する。
M_o_R
英国 OGC (Office of Government Commerce) による M_o_R (Management of Risk) フレームワークに基づくリスクマネジメントでは,"原則","アプローチ","プロセス","組込みとレビュー" の四つの概念に基づくフレームワークを適用し,プロセスは "識別","評価","計画","実施" のステップに従ってリスクを管理する。
ISO31000
ISO31000 に基づくリスクマネジメントでは,"コミュニケーション及び協議","組織の状況の確定","リスクアセスメント","リスク対応","モニタリング及びレビュー" の五つのプロセスに基づき,リスクを管理する。また,"リスクマネジメントは,不確かさに明確に対処する" といったリスクマネジメントの 11 の原則を遵守して,効果的にリスクを管理する。
- 成功事例。規範となる業務の進め方を指す。
(4) SLA
SLA
SLA (Service Level Agreement) は,発注者とサービス提供者との間で,サービスの品質の内容について合意した文書のこと。
内容は,サービスの品目と水準,水準が達成できなかった場合のペナルティなどが盛り込まれ,サービスレベルは客観的な方法で測定できる数値で記載される。
IT サービスの可用性と信頼性の管理に関わる KPI として,サービスの中断回数及びそのインパクトの削減率が用いられる。
例として,ある会社の基幹サービスの SLA の抜粋を次表に示す。
| 種別 | サービスレベル | 目標値 | 備考 |
|---|---|---|---|
| 可用性 | サービスの提供時間帯 | 毎日 8:00 ~ 22:00 | 保守のための計画停止時間を除く。 |
| サービス稼働率 | 99.9 % 以上 | - | |
| 信頼性 | 重大インシデント件数 | 年 4 件以下 | - |
| 重大インシデントの解決時間 | 2 時間以内 | インシデントを受け付けてから最終的なインシデントの解決を基幹システムを利用する部門に連絡するまでの経過時間(サービス提供時間帯以外は,経過時間に含まれない) | |
| 性能 | オンライン応答時間 | 3 秒以内 | - |
SLA の目標値は,目標保証型と努力目標型に分類される場合がある。
- 目標保証型
- 取り決めたサービスレベルを保証する。
- 努力目標型
- 取り決めたサービスレベルは努力目標にとどまり,サービスレベルの達成,維持に向けて継続的な改善努力を行う。
SLO (Service Level Object),サービスレベル目標
SLO (Service Level Object) は,通信サービスやクラウドサービスにおいて,事業者が自社のサービスレベル(サービス品質)に関する目標・評価基準を定めたもの。
サービスレベル管理プロセスにおける代表的な管理指標を次表に示す。
| 関連プロセス | サービスレベル項目 (SLO) | 目標値設定例 |
|---|---|---|
| サービス全体 | サービス時間 | 月 ~ 金,8:00 ~ 20:00 |
| サービスデスク | 平均応答時間 | 20 秒 |
| 一次窓口回答率 | 60 % | |
| インシデント管理 | 平均インシデント検知報告時間 | 10 分 |
| 平均インシデント解決時間(ランク別) | A(重大) : 5 時間,B(重要) : 1 時間 | |
| 可用性管理 | サービス時間帯の稼働率 | 95 % |
| サービス停止時の平均復旧時間 | 1 時間 | |
| キャパシティ管理 | 平均オンライン応答時間 | 5 秒 |
| バッチ処理時間遵守率 | 95 % | |
| 情報セキュリティ管理 | 年間侵入テスト実施回数 | 2 回 |
管理指標としては上記以外にも様々な指標があるが,以下の条件を満たしている必要がある。
- 過剰な負荷をかけることなく,継続的に測定が可能な指標であること
- ビジネス部門が意味を理解でき,ビジネスの効率性や有効性に影響を与える意味のある指標であること
- サービス提供部門が,サービスレベルをコントロールできる指標であること
- サービス提供部門が,目標を達成できる指標であること
SLI (Service Level Indicator),サービスレベル指標
SLI (Service Level Indicator) は,SLO へのコンプライアンスを測定する。
サービス可用性
可用性とは,「利用者が必要なときに IT サービスを利用できる割合」のことで,一般的には稼働率という指標を用いて表される。
IT サービスの可用性は,IT サービスを構成する個々の情報システムの信頼性,保守性,サービス性の 3 つの要素に分解することができる。IT サービスの可用性向上には,こうした信頼性・保守性・サービス性の 3 つの観点から,適切にサービスを設計していくことが必要となる。

信頼性
信頼性は,IT サービスを構成するコンポーネントが故障しづらいことを示す指標であり,停止する間隔である平均故障間隔 (MTBF : Mean Time Between Failure) で表される。
サービス時間
サービス時間は,サービスレベル項目に用いられる。
応答時間
応答時間は,サービスレベル項目に用いられる。
サービス及びサービスマネジメントシステムのパフォーマンス
サービスマネジメントシステムの計画及び運用
- サービスマネジメントシステムの計画及び運用の要求事項を修得し,適用する。
(1) サービスマネジメントシステムの計画と支援
PDCA
サービスマネジメントシステム要求事項は,SMS 及びサービスのあらゆる場面で, 計画(Plan)−実行(Do)−点検(Check)−処置(Act)(PDCA)として知られる方法論の適用を要求する。この規格で適用する PDCA 方法論を簡潔に説明すると,次のようになる。
- 計画(Plan)
- SMS を確立し,文書化し,合意する。SMS には,サービスの要求事項を満たすための方針,目的,計画及びプロセスが含まれる。
- 実行(Do)
- サービスの設計,移行,提供及び改善のために SMS を導入し,運用する。
- 点検(Check)
- 方針,目的,計画及びサービスの要求事項について,SMS 及びサービスを監視,測定及びレビューし,それらの結果を報告する。
- 処置(Act)
- サービスマネジメントシステム及びサービスのパフォーマンスを継続的に改善するための処置を実施する。
PDCA サイクルは,あらゆるプロセス及び品質マネジメントシステム全体に適用できる。
JIS Q 9001
JIS Q 9001:2015「品質マネジメントシステム−要求事項」"Quality management systems-Requirements " は,2015年に第5版として発行された ISO 9001 を基に,技術的内容及び構成を変更することなく作成した日本工業規格である。
マネジメントシステム
JIS Q 9001:2015「品質マネジメントシステム−要求事項」において,品質マネジメントの原則とは,次の事項をいう。
- 顧客重視
- リーダーシップ
- 人々の積極的参加
- プロセスアプローチ
- 改善
- 客観的事実に基づく意思決定
- 関係性管理
資源
組織は,品質マネジメントシステムの確立,実施,維持及び継続的改善に必要な資源を明確にし,提供しなければならない。
組織は,次の事項を考慮しなければならない。
- 既存の内部資源の実現能力及び制約
- 外部提供者から取得する必要があるもの
力量
組織は,次の事項を行わなければならない。
- 品質マネジメントシステムのパフォーマンス及び有効性に影響を与える業務をその管理下で行う人(又は人々)に必要な力量を明確にする。
- 適切な教育,訓練又は経験に基づいて,それらの人々が力量を備えていることを確実にする。
- 該当する場合には,必ず,必要な力量を身に付けるための処置をとり,とった処置の有効性を評価する。
- 力量の証拠として,適切な文書化した情報を保持する。
注記 適用される処置には,例えば,現在雇用している人々に対する,教育訓練の提供,指導の実施,配置転換の実施などがあり,また,力量を備えた人々の雇用,そうした人々との契約締結などもあり得る。
認識
組織は,組織の管理下で働く人々が,次の事項に関して認識をもつことを確実にしなければならない。
- 品質方針
- 関連する品質目標
- パフォーマンスの向上によって得られる便益を含む,品質マネジメントシステムの有効性に対する自らの貢献
- 品質マネジメントシステム要求事項に適合しないことの意味
コミュニケーション
組織は,次の事項を含む,品質マネジメントシステムに関連する内部及び外部のコミュニケーションを決定しなければならない。
- コミュニケーションの内容
- コミュニケーションの実施時期
- コミュニケーションの対象者
- コミュニケーションの方法
- コミュニケーションを行う人
文書化した情報
組織の品質マネジメントシステムは,次の事項を含まなければならない。
- この規格が要求する文書化した情報
-
品質マネジメントシステムの有効性のために必要であると組織が決定した,文書化した情報
注記 品質マネジメントシステムのための文書化した情報の程度は,次のような理由によって,それぞれの組織で異なる場合がある。- 組織の規模,並びに活動,プロセス,製品及びサービスの種類
- プロセス及びその相互作用の複雑さ
- 人々の力量
知識
(2) サービスの計画
サービスの要求事項
変更要求
サービスポートフォリオ
サービスポートフォリオとは,サービス・プロバイダによって管理されている全てのサービスをリスト化し,そのサービスごとに詳細情報をまとめたものである。その対象範囲を下図に示す。
サービス・プロバイダの約束事項と投資を表すものであって,サービス・プロバイダによって管理されている "検討中か開発中","稼働中か展開可能" 及び "廃止済み" の全てのサービスが含まれる。

サービス・パイプライン
サービス・パイプラインには,将来提供する予定である開発中のサービスが収録される。サービス・パイプラインに収録されているサービスは,顧客には公開されない。
サービスの状態(計画中,開発中,稼働中,廃止など)
(3) サービスカタログ管理
サービスカタログ
サービスの販売と提供の支援に使用され,顧客に公開されるものであって,"検討中か開発中" と "廃止済み" のサービスは含まれず,"稼働中か展開可能" のサービスだけが含まれる。
サービスカタログとは,サービスプロバイダ(情報システム部門/外部サービス事業者)がエンドユーザー(従業員/顧客)に向けて提供中の IT サービスをまとめたリストのこと。現状において稼動中で利用可能な IT サービスを一覧できるようにした文書やデータベースなどをいう。サービスカタログの認可は,サービスオーナが責任をもつ事項である。
サービスカタログは,IT サービスを受けるエンドユーザーに「いま利用できる IT サービスには何があるか」「すでに利用している IT サービスはどれか」などの情報を明確に提示するものである。従って,IT サービスを利用するうえでは不要な技術的説明などは省き,IT に詳しくない利用者にも理解できるような言葉遣いで表現すべきである。
サービス・カタログとは「稼働中の全ての IT サービス(展開可能な IT サービスを含む)に関する情報を格納するデータベースまたは構造化された文書」(出典「ITIL 用語および頭字語集」)
サービスカタログには,通常以下の内容が記述される。
- サービスの名称およびサービスの概要
- サービスのタイプ
- ビジネスオーナー,ビジネスユニット
- サービス管理者
- ビジネスへのインパクトおよび優先度
- サービスレベル・サービス提供時間
- サービスレポートおよびサービスレビュー会議
- サービス料金
- 問合せ窓口
(4) 資産管理
資産管理(IT アセットマネジメント(ITAM:IT asset management))
サービスを提供するために使用される資産を管理することを求めている。
ソフトウェアアセットマネジメント(SAM)
組織が所有する各種のソフトウェア資源についての管理を適切に行う。
自社で開発したソフトウェアや外部から購入したソフトウェアについて,それぞれの特性を考慮した管理作業が必要となる。自社で開発したソフトウェアについては,企画,開発,保守,廃棄に至るまでのプロセスを効率よく実施し,仕様とその背景にあるユーザ要求を,履歴も含め正しく保存する。外部から購入したソフトウェアについては,違法複製を防止し,ライセンス契約の利用条件を満たしたうえで,最適数のライセンスを購入する。また,アプリケーションの修正パッチ,特にセキュリティパッチの適用や,サポート期間などを考慮する。
管理手順の作成にあたっては,「ソフトウェア管理ガイドライン」が参考になる。
ライセンスマネジメント
ソフトウェアパッケージの普及やソフトウェア部品の利用増加により,ライセンス料金がアプリケーション費用の大部分を占める場合が多くなっている。
(5) 構成管理
構成管理
構成管理プロセスは,すべてのサービス資産と構成およびその関係を特定して構成管理データベース(CMDB)を構築し,それらサービス構成要素の維持管理や制御を活動の中心とするプロセスである。構成管理データベースには,構成品目,版,関係,ベースライン及びリリースなどの構成情報が記録され,他のプロセスからの求めに応じて情報の提供を行う。既知のエラーレコードを作成してデータベースに登録するのも,構成管理プロセスで行う活動である。
構成管理を導入することで,構成品目の情報を正確に把握することによって,他のプロセスの確実な実施を支援できる,というメリットが得られる。
構成品目(CI : Configuration Item)
サービス資産・構成管理プロセスにおける管理の単位を構成品目 (CI : Configuration Item) と呼ぶ。ITIL では構成品目の種類の例として,以下の分類を行っている。
| CI の種類 | 具体例 |
|---|---|
| サービスライスサイクル CI |
|
| サービス CI |
|
| 組織 CI |
|
| 内部 CI |
|
| 外部 CI |
|
| インタフェース CI |
|
構成情報
文書化された構成情報(例:構成管理データベース(CMDB : Configuration Management Database))
構成品目のライフサイクルを通じて,構成品目の属性及び構成品目間の関係を記録するために使用するデータベース。
すべてのインシデントはインシデント・レコードとして記録され,発生から完了までのライフサイクルが管理される。インシデント・レコードは,インシデントを管理する特定のデータベースもしくは構成管理システム(CMS : Configuration Management System)に格納される。
CMDB の記録は,変更の展開の成功後に更新する。
版(バージョン)
構成ベースライン
サービスマネジメントにおいて,ある時点での構成品目(CI)群のスナップショットを構成ベースラインという。構成ベースラインは,CI を追加する際の標準 CI として利用したり,障害発生時の切り戻しの復旧ポイントとして利用したり,構成監査を行う際の基準となる情報として利用したりする。
構成識別
構成監査
(6) 事務関係管理
事業関係管理
サービスマネジメントの "事業関係管理" において,サービス提供者が実施すべき活動は,「サービスの顧客,利用者及び他の利害関係者を特定し,文書化し,顧客及び他の利害関係者との間にコミュニケーションのための取決めを確立する。」である。
事業関係マネージャは,事業関係管理について責任をもつ役職で,顧客との関係維持を責務とする役割である。
顧客関係
顧客満足
サービス満足度
苦情
(7) サービスレベル管理
サービスレベル管理(SLM : Service Level Management)
サービスレベル管理(SLM : Service Level Management)の最終目標は,現在のすべての IT サービスに対して合意されたレベルを達成すること,そして将来のサービスが,合意された達成可能なサービスレベル目標を満たすように提供されることである。
サービスレベル管理プロセスの活動として,提供するITサービス及びサービス目標を特定し,サービス提供者が顧客との間で SLA(Service Level Agreement)を交わす。
SLA の締結後は,PDCA マネジメントサイクルによってサービスの維持,及び向上を図る活動を行う。
ビジネス部門がサービスレベル管理プロセスを導入するメリットを示す。
- ビジネス要件に適したサービスレベル目標値が設置されることで,安定した IT サービスを受けることができ,ビジネスの安定性を向上させることができる。
- サービスレベルがビジネスの重要性と整合しているかを把握することができ,IT サービスの費用対効果が評価しやすくなる。
IT サービス提供部門がサービスレベル管理プロセスを導入するメリットを示す。
- ビジネス部門とのコミュニケーションが促進され,ビジネスの要求の正確な把握ができる。
- 定量的にサービスレベルを評価することで,IT サービスのパフォーマンスを客観的に評価することができ,ビジネス部門や経営者に対する説明責任を果たすことができる。
- ビジネスの要求に適した IT サービスの設計・提供が可能となり,不要または過剰な IT サービスを排除することができる。
サービスレベル目標
パフォーマンス
(8) 供給者管理
供給者管理
供給者管理は,すべての供給者との契約と供給者が提供するサービスを管理するプロセスである。供給者管理においては,重要度の高い供給者に対してより多くの管理コストをかけるべきである。
サービス提供者が委託などにおいて,さらにサービスマネジメントプロセスの導入や移行のために供給者(サプライヤ)を用いる場合には,その供給者の管理が必要である。運用を委託する場合には,運用レベルを保証するために OLA(Operation Level Agreement : 運用レベル合意書)を作成し,契約を行う。
供給者管理における主要な KPI には,次のものがある。
- 合意した目標値を達成する供給者数の増加
- 供給者と契約に関する目標値の数の増加
- 供給者に起因するサービス違反数の減少
外部供給者
IT サービスを提供する際に,業務の一部や全てを外部委託すること,IT サービスの基盤に外部のデータセンタやクラウドサービスを活用することなど,提供者が提供するサービスを利用することが広く行われている。
内部供給者
供給者として行動する顧客
契約
供給者管理における契約には,要件定義,評価,確立がある。
- 新しい供給者および契約の要件定義
- サービスの設計の一環として,新たな供給者の支援が必要か,どの程度必要なのかを定義する。
- 新しい供給者と契約の評価
- 新たな提供者が提供するサービス,リスク,コストなどを評価する。
- 新しい供給者と契約の確立
- 新たな供給者と契約を結び,サービスを移行する。
アウトソーシングの利用
外部のリソースを利用する。
SaaS,PaaS,IaaS などのクラウドサービスの利用
クラウドサービス上にデータを保存している場合,急なサービス提供停止により重要なデータが消失してしまうというリスクがある。そのためクラウドサービスを選定する際には,導入・運用コストなどの検討とあわせて,サービス提供事業者が「そのサービスを長期に渡り提供し続けてくれるどうか」や「利用終了時のデータの取扱い」という点を考慮する必要がある。
SaaS 選定の観点を次表に示す。
| 番号 | 項目 | SaaS 選定の観点 |
|---|---|---|
| 1 | サービス仕様 | ① 想定する業務に必要なサービス・機能が充実しているか ② サービスがメニューとして豊富に用意されているか |
| 2 | サービスレベル | ① 性能,サービス時間,サービスの稼働率,障害発生頻度,目標復旧時間が現状よりも良好な水準か ② 複数のサービスレベルが用意されているか |
| 3 | セキュリティ対策 | ① 物理的対策,データバックアップ方法,機器障害対策,ソフトウェア脆弱性対策,不正アクセス対策,データ機密性対策などが情報セキュリティポリシに合致しているか |
| 4 | サービス利用終了時対応 | ① 利用期間中に保管されていたデータが返却されるか ② SaaS 利用に関する全てのデータは,利用者に返却後,確実に消去されるか |
| 5 | 経営基盤 | ① 財務情報からサービス提供者の経営が安定していると判断できるか ② 同業他社を含めて,利用している企業が多数存在するか |
(9) サービスの予算業務及び会計業務
サービスの予算業務及び会計業務
財務管理
予算業務
サービス提供にかかわる収入と支出を予測し,コントロールする。
会計業務
サービス提供のために投入された資金やかかったコストを管理する。
課金
サービス提供にかかった費用を顧客から回収するために,使用時間や使用量などに応じて料金を設定し,請求を行う。
配賦
直接費
間接費
減価償却
総所有コスト(TCO : Total Cost of Ownership)
TCO (Total Cost of Ownership) は,ある設備・システムなどにかかわる,購入から廃棄までに必要な時間と支出の総計金額のことである。
(10) 需要管理
需要
各種サービスに対するニーズの量。
需要管理
各種サービスに対するニーズの量(つまり「需要」)を総合的に把握して管理することで,より効率的に良いサービスをお客様に提供することができるようになる。これを需要管理と呼ぶ。
需要管理とは「サービスに対する顧客の需要を把握,予測し,それに影響を及ぼすことを責務とするプロセス」(出典「ITIL 用語および頭字語集」)
需要予測
(11) 容量・能力管理
容量・能力(キャパシティ)
システムが備えるべき能力(キャパシティ)を管理する。キャパシティは,現在および将来の需要を考慮して計画・設計を行う。また,サービスのパフォーマンス(CPU 使用率,メモリ使用率,ディスク使用率,ネットワーク使用率ほか)のしきい値を設定・監視し,キャパシティ拡張の判断を行う。
キャパシティ管理に関わる必要な活動として,リソースの増強を適切に(過不足なく)行う必要がある。
容量・能力計画
ITIL におけるキャパシティ管理では,事業キャパシティ,サービスキャパシティ,コンポーネントキャパシティという三つの異なる観点から,対象となる IT サービスに必要なキャパシティを計画・実装し,管理する。このうち,コンポーネントキャパシティ管理では,サービスを提供する IT インフラの個々の構成アイテム(コンポーネントやリソースともいう)の容量や利用状況がどのように変化していくかというデータを把握し,分析することで,適切なキャパシティを計画し実現させる。
容量・能力管理
オンラインシステムの容量・能力の利用の監視についての注意事項は,応答時間や CPU 使用率などの複数の測定項目を定常的に監視する。
キャパシティ管理では,サービスにどの程度のリソースやパフォーマンス(機能)が必要となるかを将来を見据えて管理する。リソースには,CPU やメモリといったシステム的なものだけでなく,人的リソースや工数管理も含まれる。
- スケールアップ
- サーバを構成する各処理装置をより性能の高いものに交換したり,プロセッサの数などを増やすことでサーバ当たりの処理能力を向上させる
- スケールアウト
- 接続されるサーバの台数を増やすことでサーバ群全体としての処理能力や可用性を向上させる
IT サービスマネジメントの容量・能力管理では,ITIL のキャパシティ管理にあたる。キャパシティ管理においては,将来のコンポーネント,サービスのキャパシティ,パフォーマンスなどを予想するが,その予想にあたっては,さまざまな方法でモデル化を行う。モデル化は,次の 4 段階で行われる。
- 第 1 段階:ベースラインのモデル化
- これは,現在達成されているパフォーマンスを正確に反映するベースライン・モデルを作成する作業である。この作業によって,起こりうる障害や変更の結果の精度が信頼できるものになる。
- 第 2 段階:傾向分析
- キャパシティ管理プロセスによって収集されたリソースの利用状況やサービスのパフォーマンスについて,傾向分析や予測を行う。この作業には,スプレッドシート,グラフなどが用いられる。
- 第 3 段階:分析モデル化
- 待ち行列理論などの数学的技法を利用して,コンピュータシステムの動作をモデル化する。一般に,分析モデル化では,ソフトウェアパッケージを用いて,コンポーネントの使用率を待ち行列理論に当てはめ,応答時間などを予測する。
- 第 4 段階:シミュレーションのモデル化
- 任意のハードウェア構成に対して発生するイベントをシミュレーションし,モデル化する。この作業によって,アプリケーションのサイジングや変更における影響に関する精度の高い予測ができる。
監視
オンラインシステムの容量・能力の利用の監視では,応答時間や CPU 使用率などの複数の測定項目を定常的に監視する。
エージェント機能とは,コンピュータにユーザのエージェント(agent,代理人)のような機能をもたせたソフトウェアモジュールである。エージェント機能を利用した運用監視の例として,監視対象機器内の監視プログラムがリソースの使用状況を監視し,しきい値を超えたら監視サーバに通知することが挙げられる。
しきい(閾)値
管理指標(CPU 使用率,メモリ使用率,ディスク使用率,ネットワーク使用率ほか)
ディスク使用率は,磁気ディスクという構成アイテムの状況を監視する項目として用いられる。
(12) 変更管理
① 変更管理方針
変更管理
変更管理は,サービスのコンポーネント,文書の変更を安全かつ効率的に行うための管理である。事業部や IT 部門などからの RFC(変更要求)を受け取り,対応する。
ITIL v3 における変更管理プロセスの考え方として,変更諮問委員会(CAB)だけではなく,緊急時の決定を下す権限を有する小規模な組織を特定しておくことも必要である。
変更管理では,変更のアセスメントする際に確認すべき項目を 7 つの R としてまとめている。これらの情報を確認することで,稼働中のサービスに対して変更を実施する際の効果とリスクを適切に測ることができるようになる。
| 提起 (Raised) | 変更を提起したのは誰か? |
|---|---|
| 理由 (Reason) | 変更の理由は何か? |
| 見返り (Return) | 変更によって得られる見返りは何か? |
| リスク (Risk) | 変更に伴うリスクは何か? |
| リソース (Resource) | 変更に必要なリソースは何か? |
| 責任者 (Responsible) | 変更の責任者は誰か? |
| 関係 (Relationship) | 変更は他にどの変更と関係しているか? |
変更管理方針
② 変更管理の開始
変更要求(RFC)
RFC (Request For Change) は,インシデント管理プロセスや問題管理プロセスから発行される変更要求である。RFC を受けて実際にシステム構成を変更するのは変更管理プロセスでの活動である。
RFC 管理項目と起票時の記入要領の例を示す。(出典)平成29年度 秋期 IT サービスマネージャ試験 午後Ⅰ 問題 問2「問題管理及び変更管理」
| 項番 | RFC 管理項目 | 起票時の記入要領 |
|---|---|---|
| 1 | 変更要求番号 | 記入しない(RFC の一連番号であり,変更管理マネージャが RFC を受け付けたときに付番する)。 |
| 2 | 件名 | 変更の内容が分かる名称を記入する。 |
| 3 | 起票日 | 記入しない(RFC の受付年月日であり,変更管理マネージャが RFC を受け付けたときに記入する)。 |
| 4 | 起票者 | RFC を起票した者の所属及び氏名を記入する。 |
| 5 | 変更対象の CI | 変更の対象となる CI を記入する。版などの CI の属性が必要な場合は属性情報も記入する。 |
| 6 | 変更種別 | 別途,定めている規則に従って,軽微,重要,重大のうちいずれかを記入する。 |
| 7 | 変更内容 | 変更の概要を記入する。 |
| 8 | サービスの要求事項 | サービスの要求事項を記入する。 |
| 9 | 事業利益 | 変更の実施によって得られる事業上の利益を記入する。 |
| 10 | 優先度 | 緊急又は通常のどちらかを記入する。。 |
| 11 | 要求納期 | 変更を実施する期限を記入する。 |
| 12 | サービス及び顧客への潜在的影響 | 変更を実施しない場合のサービス及び顧客への影響を記入する。 |
| 13 | リスク | 変更を実施することによって発生する可能性があるリスクを記入する。 |
| 14 | 技術的実現可能性 | 起票時点において分かる範囲で,変更に必要な資源及びキャパシティを記入する。 |
| 15 | 工数,費用などの財務的な影響 | 変更に必要な工数,費用などを記入する。 |
| 16 | 変更の責任者 | 予定している責任者を記入する。 |
| 17 | 他の変更との関係 | 関連する変更がある場合は,該当する変更要求番号を記入する。 |
③ 変更管理の活動
変更管理方針で定義された構成品目に対する変更要求の管理を実施する。
優先度
変更管理の優先度は,緊急または通常に分類される。
変更のカテゴリ(標準変更,通常変更,緊急変更など)
標準変更とは,リスクが低く,比較的よくあり,手順又は作業指示書に従う事前認可済の変更である。
通常変更とは,計画どおりのサービス変更で,標準変更でも緊急変更でもないものである。
緊急変更とは,早急に実施することが望ましい変更で,例えば,重大なインシデントの解決又は情報セキュリティパッチの実施を目的としたものである。
ロールバック(切り戻し)
変更諮問委員会(CAB)
IT サービスに変更を加える要因には,単純なオペレーションだけでなく事業戦略やビジネスプロセスの変更など,様々なものがある。そのため,顧客やユーザ,開発者,システム管理者,サービスデスクなどの様々な立場の利害関係者が定期的に集まり,変更をアセスメントする変更諮問委員会(CAB : Change Advisory Board)が開かれる。
ITIL における変更諮問委員会 (CAB : Charge Advisory Board) とは,提出された RFC(変更要求)を評価し,変更のアセスメント,優先度付け,およびスケジューリングにおいて変更マネージャに助言を与える組織である。CAB は,顧客(経営者層)の代表,ユーザ(サービスの利用者)の代表,技術的専門家,外部サプライヤなど,部門横断型の階層から招集され,RFC をビジネスの観点から評価する。ただし,RFC の最終承認やそれに基づく変更計画の作成を直接行う組織ではない。
開催を通知された CAB 要員が開催日時に CAB に参加できない場合がある。このような場合,CAB 要員は RFC の内容を事前に確認し,リスクアセスメントを行い,結果を CAB へ提出する。
変更実施後のレビュー(PIR : Post-Implementation Review)
実施変更後に行うレビュー。プロジェクトなどの活動終了後に行うレビューで,活動が成功したかどうかを判断する。
(13) サービスの設計及び移行
① 新規サービス又はサービス変更の計画
サービスの設計及び移行
新規サービス又はサービス変更の計画
サービスまたは顧客に重大な影響を及ぼす可能性のある「新規サービス」や「サービス変更」が起きた場合に,サービス提供者が実施すべき適切な手順や活動,考慮すべき内容等を定めている。
新規または変更したサービスを本格的な稼働状態へ移行する場合は,以下に示すような手順を踏まえる必要がある。
- 試験環境を用意し,事前に試験(受入れテストや運用テスト)を実施する。また,稼働環境へ移行する際の切替え手順や問題点を確認するために移行テストを実施する。
- 1. で問題がなければ稼働環境へ移行(一斉移行方式,段階的移行方式,並行移行方式など)させる。
開発から運用への移行を円滑かつ効率的に進めるには,システムの開発部と顧客(または運用部)が連携し,顧客もシステムの運用に関わる要件の抽出に積極的に参加することが重要になる。
② 設計
サービスの設計は,経営戦略で定められた事業のニーズを満たすために行われる。SLA などで定められた,具体的な数値を満たすために必要なサービスの設計を行う。
サービス受入れ基準
設計・開発
サービス設計書
非機能要件
性能,信頼性,拡張性,セキュリティなどのように,システム自体に求められる業務要件や入出力など以外のもの全般を指す。
③ 構築及び移行
構築
継続的インテグレーション (CI : Continuous Integration)
各開発者が作成するソフトウェアのコードを定期的に(1 日に数回などの頻度で)セントラルリポジトリにマージする手法。その都度ビルドとテストを自動実行する。チームでのソフトウェア開発によって発生しやすい各開発者による競合を少なくし,迅速に開発を進めることができる。
移行
運用サービス基準
業務及びシステムの移行
現行システムの登録データと新システムへの移行内容を次表に示す。
| 番号 | 登録データ | 移行内容 |
|---|---|---|
| 1 | 顧客データ | 直近 5 年間に取引又は引き合いがあった顧客のデータを移行する |
| 2 | 案件データ | 移行対象となる顧客に関する直近 5 年間の案件のデータを移行する |
| 3 | 営業活動データ | 移行対象となる案件に関する直近 5 年間の営業活動のデータを移行する |
| 4 | 広告・営業活動データ | 直近 5 年間の広告・宣伝活動のデータを移行する |
| 5 | 利用者データ | 現行営業支援システムからは移行せず,人事システムから必要なデータを取得する |
移行計画
移行リハーサル
切換計画に不備がないことを確認するために,システム切替作業の実施日より前に実施するもの。
移行判断
移行の通知
移行評価
運用テスト
受入れテスト
運用引継ぎ
(14) リリース及び展開管理
リリース及び展開管理
変更管理プロセスで承認された変更内容を,IT サービスの本番環境に正しく反映させる作業(リリース作業)を行うのが,リリース及び展開管理である。
リリース管理では,本番環境にリリースした確定版のすべてのソフトウェアのソースコードや手順書,マニュアルなどの CI(構成品目)を 1 か所にまとめて管理する。まとめておく書庫のことを DML(Definitive Media Library : 確定版メディアライブラリ)という。
リリース
IT サービスマネジメントにおいて,リリース管理からインシデント管理に伝達することが望ましいとされている情報は,リリースするものに含まれている既知の誤りである。
緊急リリースを含むリリースの種類
展開
リリースの受入れ基準
受入れ試験環境
稼働環境
リリースの配付
継続的デリバリ (CD : Continuous Delivery)
コード変更が発生するたびに自動で実稼働環境へのリリース準備を実行する手法。CI を拡張したものであり,開発者による全てのコード変更が,ビルドやテストを経て,本番環境にリリースできる状態に自動で準備される。
継続的デプロイ
CD には,さらにその先の本番環境へのリリースまでを自動化する考え方もあるが,本番環境へのリリースだけは人間による判断を介する場合は継続的デリバリ,すべて自動化される場合を継続的デプロイと呼び,区別することもある。
(15) インシデント管理
インデント管理は,"計画外の障害"や "顧客からのサービス障害報告" からのサービスの迅速な復旧を行う管理を行う。
① インシデントの対応
インシデント管理
インシデント管理は,サービスに対する計画外の中断,サービスの品質の低下,あるいは顧客へのサービスにまだ影響していない事象が報告された時に,サービスの中断時間を最小限に抑えて速やかに回復することを目指すプロセスである。インシデント管理プロセスには,例として,ITサービスを迅速に復旧させるために回復策を実施する活動,インシデントの発生を記録し,関係する部署に状況を連絡する活動がある。
インシデント管理の手順は,以下の通り。
| 手順 | 内容 |
|---|---|
| 記録・分類 |
|
| 優先度付け |
|
| エスカレーション |
|
| 解決 |
|
| 終了 |
|
- 注1) インシデント管理ファイルにはインシデントだけでなく質問とその回答内容も記録される。
- 注2) 対応手順書は,インシデントに対応するために実施すべき解決処理の詳細が記載されている手順書のことで,サービスデスクが作成し整備する。対応手順書には,インシデントが及ぼすサービスへの影響を低減又は除去する方法を特定した場合の対応手順も記載されている。
通常,インシデント管理では,次のような KPI(Key Performance Indicator)が設定される。
- サービスデスクで解決された割合(初回解決の割合)
- 解決までの平均時間
- 重大なインシデントの数・割合
- 目標時間内に解決できた割合
インシデント
インシデントとは,IT サービスの停止,または,サービス品質を低下させる事象を指す。インシデント管理プロセスでは,既に IT サービスの停止や品質の低下を招いているものだけではなく,今後そのような事象が発生する可能性のあるものも含めてインシデントとして管理対象としている。
記録
すべてのインシデントはインシデント・レコードとして記録され,発生から完了までのライフサイクルが管理される。インシデント・レコードは,インシデントを管理する特定のデータベースもしくは構成管理システム(CMS : Configuration Management System)に格納される。
分類
影響
インシデントが事業に及ぼす英y公。
緊急度
インシデントが事業に重大なインパクトを及ぼすまでにどれくらいの猶予があるか。
優先順位
インシデントの優先度は,緊急度とインパクトの両面から評価する。例えば,緊急度とインパクトを大きく三段階(高/中/低)に分け,次表のように 5 段階のコードをつける。
| インパクト | ||||
|---|---|---|---|---|
| 高 | 中 | 低 | ||
| 緊急度 | 高 | 1 | 2 | 3 |
| 中 | 2 | 3 | 4 | |
| 低 | 3 | 4 | 5 | |
解決目標時間
エスカレーション(機能的エスカレーション,階層的エスカレーション)
インシデントの早期解決のために,インシデントを受け付けた 1 次グループが,より対処能力に優れた専門的な部門や権限を持つ上位組織(2 次グループ)などにインシデントの解決を依頼すること。
- 階層的エスカレーション
- エスカレーションを支援するために,より上級レベルのマネジメントに情報を提供したり,彼らを関与させたりすること。
- 機能的エスカレーション
- エスカレーションを支援するために,より高度な専門知識を持つ技術チームにインシデント,問題,または変更を転送すること。
回避策(ワークアラウンド)
ITIL におけるワークアラウンドは,インシデントや問題に対する完全な解決策がまだ存在しないときの暫定処置のことである。
インシデント発生時の回復策のことで,完全な解決策がまだ存在しないインシデントや問題の悪影響を低減または排除するために策定される。問題やエラーコードごとのワークアラウンドを用意することで,業務の停止時間を最小限に抑えることができる。
終了
インシデントモデル
インシデントモデルは,特定の種類のインシデントに対して,とるべきプロセス,責任者,対応のために許容される時間,しきい値,エスカレーション手順などを事前に定義したものである。インシデントモデルを定義しておくことで,同種のインシデントが発生した際に,事前に定義した経路で,事前に定義した時間枠内で対応することが可能である。
② 重大なインシデントの対応
重大なインシデント
インシデントのインパクトが最上位のカテゴリに入ると評価されたインシデント。重大なインシデントは,事業中断の原因となるため,あらかじめ重大インシデント手順を定めておき,それに沿って対応を行う。
ミッションクリティカルシステム
ミッションクリティカルシステムは,障害発生などによってシステムが中断・停止すると巨額の損失や信用の失墜などの致命的な問題を招く可能性が高いため,24 時間 365 日止まることを許されないシステムをいう。
交通機関や金融機関の基幹システム,および EC サイトの基幹システムなどがミッションクリティカルシステムの例で,これらのシステムでは停止をさせないために極めて高い信頼性や耐障害性,保守性などが要求される。
(16) サービス要求管理
サービス要求管理
サービス要求管理は,顧客やユーザが発するサービス要求に応える活動である。
サービス要求
サービス要求とは,対処方法が確立されており,インシデント管理や変更管理が対応するには及ばない「ちょっとした」要求や変更のことである。サービス要求の多くは,低リスク,低コストで,発生頻度が高い。サービス要求の例として,次のものがある。
- パスワードを再発行してほしい。
- 追加アプリケーションをインストールしたい。
- サーバに関する情報を教えてもらいたい。
記録
すべてのサービス要求を記録する。
分類
緊急度
優先順位
実現
要求モデルに従って,サービスデスクや専門のサポートチームがサービス要求を実現する。
終了
ユーザが結果に満足したかを確認したうえで,サービス要求をクローズする。
サービス要求の実現に関する指示書
(17) 問題管理
問題管理
問題管理プロセスは,インシデントの根本原因を特定し,インシデント及び問題の影響を最小化又は回避することを目的とするプロセスである。主な活動は以下の通り。
- インシデントの根本原因と潜在的な予防処置を特定する
- 問題解決のための変更要求を提起する
- サービスへの影響を低減又は除去するための処置を特定する
- 既知の誤りを記録する
したがって,IT サービスマネジメントにおける問題管理プロセスにおいて,インシデントの発生後に未知の根本原因を特定し,恒久的な解決策を策定する。
問題管理の活動は,リアクティブな問題管理とプロアクティブな問題管理に分かれる。
- リアクティブな問題管理
- インシデントやイベントの発生,サービスデスクからの報告などを契機として実行する受動的な活動。
- プロアクティブな問題管理
- 事前予防的な問題管理であり,これまでに発生したインシデントの傾向を分析して,そこに潜在する問題点を見いだし,解決策を講じて新たなインシデントの発生を予防する積極的な活動。改善活動として推進させることも多い。プロアクティブな問題管理が進めば,インシデントの発生が減少し,結果としてリアクティブな問題管理の減少も期待できる。
問題管理プロセスの手順の例を示す。(出典)平成29年度 秋期 IT サービスマネージャ試験 午後Ⅰ 問題 問2「問題管理及び変更管理」
| No. | 手順 | 内容 |
|---|---|---|
| 1 | 識別 | 次の a ~ c のいずれかによって問題を識別する。
|
| 2 | 記録 | 日時など関連する問題の詳細を記録する。また,手順 1 識別が a. の場合(以下,インシデント発生ケースという)は,問題の記録の発端となったインシデントの相互参照などを記録する。 |
| 3 | 優先度の割当て | 関連するインシデントがある場合は,関連するインシデントの緊急度及び影響に応じて解決の優先度を割り当てる。関連するインシデントがない場合は,独自に解決の優先度を設定する。優先度は高,又は低のいずれかを割り当てる。 |
| 4 | 分類 | インシデントを管理するプロセスで使用しているものと同一の分類基準を利用して問題を分類する。 |
| 5 | 記録の更新 | 問題の追跡ができるように,問題の進捗状況を捉え,記録を更新する。 |
| 6 | 段階的取扱い | 必要な場合は,該当する当事者に対して段階的取扱いを行う。 |
| 7 | 解決 |
① 調査と診断
② 既知の誤りの文書化
③ 問題の解決
|
| 8 | 終了 |
|
問題(problem)
一つ以上のインシデントの根本原因。(出典)JIS Q 20000-1:2011
傾向分析(trend analysis)
インシデントの発生を未然に防ぐためには,今後どのようなインシデントが発生するのかを予測し,予防措置を講じることで影響を最小限にとどめることが必要である。そのためには,インシデント及び問題の傾向を分析し,根本原因及び潜在的な予防措置を特定することが前提となる。サービスマネジメントにおけるこの作業を傾向分析という。
根本原因
インシデントまたは問題の,根本的な,あるいは元の原因を意味する。
予防処置
記録(record, noun)
達成した結果を記述した,又は実施した活動の証拠を提供する文書。
分類
問題をカテゴリに分類し,インシデント管理と同様の方法で,適切なコードを付ける。
優先順位付け
インシデント管理と同様の方法で,問題に優先順位を付ける。
エスカレーション
インシデント管理と同様の方法で,問題をエスカレーションする。
解決
解決策を見いだして問題を解決する。解決に構成アイテムの変更や修正が必要であれば,RFC を変更管理に提出する。
終了
問題が解決したら,該当の問題レコードをクローズする。
既知の誤り(known error)
根本原因が特定されているか,若しくは回避策によってサービスへの影響を低減又は除去する方法がある問題。(出典)JIS Q 20000-1:2011
既知の誤りは,既知のエラーデータベース(KEDB : Known Error DataBase)に格納される。
(18) サービス可用性管理
サービス可用性管理
サービス継続及び可用性管理は,SLA で合意したサービス継続及び可用性を達成することを目的とし,サービス障害や災害の予防及びそこからの復旧,並びに目標達成のための十分なサービスの可用性の提供を確実にするプロセスである。
サービス継続及び可用性管理の主要な活動は,リスクアセスメントとリスクマネジメントであり,リスクアセスメントでは重大なサービスの停止から事業が受けるインパクトを調査する事業影響度分析を実施することが望まれる。リスクアセスメント及び事業影響度分析に基づいてサービス継続計画が策定される。
- サービス障害分析 (SFA : Service Failure Analysis)
- サービス障害分析 (SFA : Service Failure Analysis) は,さまざまなデータを使ってサービスの中断の根本原因を究明し,可用性の不足が発生している状況をアセスメントするのに用いられることから,可用性管理のリアクティブな活動で用いられる技法といえる。
- 故障樹解析 (FTA : Fault Tree Analysis)
- 故障樹解析 (FTA : Fault Tree Analysis) は,障害がどのように連鎖してサービス停止に至るかを,木構造で分析する手法。可用性管理のプロアクティブな活動の一つ。
- コンポーネント障害インパクト分析 (CFIA : Conponent Failure Impact Analysis)
- コンポーネント障害インパクト分析 (CFIA : Conponent Failure Impact Analysis) は,サービスを構成する要素(CI)と提供するサービスの一覧から,CI の障害がサービスに及ぼす影響をマトリックスに示し,CI の障害に対するサービスの強さを分析する手法。可用性管理のプロアクティブな活動の一つ。
- 単一障害点分析(SPOF 分析)
- 単一障害点分析(SPOF 分析)は,障害が発生したときにインシデントの原因となる可能性のあるあらゆる CI のうち,対策の施されていないものを単一障害点 (SPOF : Single Point Of Failure) という。この単一障害点を識別し,できるだけ回避するための分析を単一障害点分析という。単一障害点の識別には,CFIA を用いるのが効果的である。
サービス可用性
サービス可用性管理の 4 つの視点は次表のとおり。
| 視点 | 能力 |
|---|---|
| 可用性 | 必要なときに合意された機能を実行する能力 |
| 信頼性 | 合意された機能を中断することなく実行する能力 |
| 保守性 | 障害発生後,迅速に通常の稼働状態に戻す能力 |
| サービス性 | 外部プロバイダが契約条件を満たす能力 |
信頼性
信頼性は,IT サービスを構成するコンポーネントが故障しづらいことを示す指標であり,停止する間隔である平均故障間隔 (MTBF : Mean Time Between Failure) で表される。
回復力
保守性
ソフトウェアの保守性の評価指標を次に示す。
MTBF
MTBF(mean operating time between failures : 平均故障間動作時間)は,故障間動作時間の期待値。平均故障隙間動作時間は,修理アイテムに対してだけ用いられる。ある特定期間中の MTBF は,その期間中の総動作時間を総故障数で除した値である。
故障動作時間が指数分布(exponential distribution)に従う場合には,どの期間をとっても故障率は一定であり,MTBF は故障率の逆数になる(故障発生率が等しければ,MTBF も等しい)。
指数関数型を含む連続分布の MTBF は,信頼度関数 $R = e^{-\lambda t}$ を用いて,次式で計算できる。
MTTR
MTTR(mean time to restoration : 平均修復時間)は,修復時間の期待値。修理を完了するための平均時間を表し,アベイラビリティ $A$,保全度 $M$,修復率 $\mu$に関係する。
連続分布関数では,修復率 $\mu$ と逆数の関係になる。
また,固有アベイラビリティ $A$ との関係では,次式がよく用いられる。
MTBF と MTTR のイメージ図を示す。

MTBSI
MTBSI (Mean Time Between Service Incidents) は,システムの稼働率で登場する MTBF の IT サービス版で,システムまたは IT サービスに障害が発生した時点から,次に障害が発生した時点までの平均時間のことである。IT サービスの信頼性の指標として使われる。MTBSI は長いほど IT サービスの信頼性が高い。
MTRS
MTRS (Mean Time to Restore Service) は,インシデントが検出されてから,対象システムまたはコンポーネントをユーザが再び利用できるようになるまでの平均経過時間。MTRS と MTTR の違いは,MTTR が対象物の修復にかかる時間を示すのに対し,MTRS はその対象物が修復された後でサービスが回復するまでにかかる時間を示すという点である。
(19) サービス継続管理
サービス継続管理では,インシデントの発生に備えて,復旧のための設計をする。
障害時には,待機系への切替え,データの回復などを行うが,その手法はあらかじめ設定しておく必要がある。BCP を策定し,RTO,RPO を決めておく。
事業継続計画(BCP)
事業継続計画 (BCP : Business Continuity Plan) は,事業継続性管理の枠組みの中で策定・実施され,事業継続マネジメントシステム (BCMS) の PDCA サイクルを通じて維持・改善されていく。近年,BCMS の国際規格も制定されており,規格に基づいた第三者認証制度である BCMS 適合性評価制度も運用されている。
BCP を策定する際の災害発生から全面復旧に至るまでの想定フェーズの例を示す。業務再開フェーズでは,優先度の高い業務を再開する。業務回復フェーズでは,優先度が高い業務を再開した後,更に業務範囲を拡大する。

ビジネスインパクト分析 (BIA : Business Impact Analysis) は,災害などが発生した際に,各業務の停止が事業の継続にどの程度のインパクトをもたらすかを分析する手法である。ビジネスインパクト分析を通じて,事業継続の上で重要となる業務を特定するとともに,復旧の目標時間を設定することができる。
| 評価項目 | 判断の性質 | 判断の根拠 | 判断する基準 |
|---|---|---|---|
| 金銭的影響 | 定量的 | 損失額 | 業務上大きな損失(金額については協議の上決定)をもたらす可能性があるかどうか |
| 法律・規制上の影響 | 定性的 | 法規制に抵触する可能性 | 法律,規制に抵触したり,当局からの業務改善命令や顧客との訴訟リスク(先数,金額)など会社経営に大きな影響を与える可能性があるかどうか |
| 顧客への影響 | 定量的 | 損失額 | 影響する顧客数,顧客に与える損失の重要度が高いもの(調査結果分析の上決定)があるかどうか |
| 株主への影響 | 定性的 | 株式価値変動の可能性 | 株式価値に著しい変動をもたらす可能性があるものがあるかどうか |
| 委託先への影響 | 定量的 | 損失額 | 影響する委託先数,委託先に与える損失の重要度が高いもの(調査結果分析の上決定)があるかどうか |
| 従業員への影響 | 定量的 | 損失額 | 従業員に著しい不利益をもたらし,結果として退職,士気の著しい低下をもたらす可能性があるかどうか |
| レピュテーション上の影響 | 定性的(重要) | 業務の性質 | 風説の流布による株価の変動や,会社信用力の大幅な失墜リスクがあるかどうか |
| 会社運営上の影響 | 定性的(重要) | 業務の性質 | 資金繰業務など停止した場合に会社経営に重大な影響を与えるかどうか |
| 社会的影響 | 定性的(重要) | 業務の性質 | 社会的に大きな影響を与える可能性があるかどうか |
サービス継続計画
復旧
RTO (Recovery Time Objective : 目標復旧時間)
業務中断後いつまでに復旧させるかを示す。例として,以下のようなものがある。
- 業務データの復旧は,障害発生時点から 24 時間以内に完了させる。
- 中断した IT サービスを 24 時間以内に復旧させる。
RPO (Recovery Point Objective : 目標復旧時点)
障害の発生などの理由により業務が中断した場合に,過去の何時の時点までの状態に戻すのかを示す目標値である。例として,以下のようなものがある。
- 障害発生時点の 24 時間前の業務データの復旧を保証する。
コールドスタンバイ
緊急時にはバックアップシステムを持ち込んでシステムを再開し,サービスを復旧する。
コンピュータシステムを設置できる施設だけを確保しておき,障害発生時にはそこに機材などを搬入してバックアップサイトとして機能させる方式。障害発生後には,システムの導入とデータの復旧を行って業務を引き継ぐ。
ホットスタンバイ(高速復旧)
バックアップサイトに本システムと同じ機器及びバックアップデータを用意しておく方式。非常時にはデータの復旧を行ってから処理を引き継ぐ。本システムを同じものを稼働させておき,定期的に同期をとる方式もこれに含まれる。
ホットスタンバイ(即時的復旧)
日常からバックアップサイトで本システムと同じものを稼働させておき,非常事態が起きたときに切れ目なく業務を引き継ぐ方式。常に本システムのデータとの同期が行われており,障害発生時に直ぐにその施設でシステムを運用できる体制になっている。
ウォームスタンバイ
別の場所にバックアップシステムを用意しておき,緊急時にはバックアップシステムを起動して,データを最新状態にする処理を行った後にサービスを復旧する。
バックアップサイトに本システムと同じ機器を全部(あるいは部分的に)設置しておく方式。障害発生後には,追加の機器やデータおよびプログラム媒体を搬入してから予備系システムを立ち上げて処理を引き継ぐ。
縮退運用
縮退運用は,システムの一部に障害が発生したときに,その障害部分を切り離し,処理速度や一部機能の制限をしてもシステム全体としては停止することなく稼働させ続ける方式である。フォールバック(fall back)ともいう。
例えば 2 台のサーバで構成される負荷分散システムにおいて,片方のサーバが故障したときに,処理能力の低下を許容して残った片方のサーバのみで処理を続けることが縮退運用に該当する。
ディザスタリカバリ(DR)
予期せぬ災害によって被害が発生した場合,迅速にサービスを回復,あるいは被害を最小限にとどめる必要がある。その回復措置をディザスタリカバリ(災害復旧),通称 DR と呼ぶ。事業継続計画(BCP)は DR を包含している。
(20) 情報セキュリティ管理
情報資産の機密性,完全性,可用性を保つように,情報セキュリティを管理する。ISMS を構築し,情報セキュリティマネジメントの規格に基づき,情報を適切に管理する。
パフォーマンス評価及び改善
- パフォーマンス評価及び改善を修得し,適用する。
(1) パフォーマンス評価
① 監視,測定,分析及び評価
② サービスの報告
サービスの報告
パフォーマンス
有効性
傾向情報
(2) 改善
① 不適合及び是正処置
不適合
是正処置
② 継続的改善
継続的改善
プロセス能力水準(プロセス成熟度水準)
プロセスアセスメント
ギャップ分析
サービスマネジメントのプロセス改善におけるベンチマーキングでは,業界内外の優れた業務方法(ベストプラクティス)と比較して,サービス品質及びパフォーマンスのレベルを評価する。
CSF(Critical Success Factors : 重要成功要因)
サービスやプロセスを成功させるために必須のもの。
KPI(Key Performance Indicator : 重要業績評価指標)
サービスやプロセスの活動を管理士評価する際に用いる測定基準のうち,特に重要なもの。
サービスの運用
- 運用計画や資源管理といったシステム運用管理の役割,機能を修得し,適用する。
- システムの操作やスケジューリングといった運用オペレーションの役割,機能を修得し,適用する。
- サービスデスクの役割,機能を修得し,適用する。
(1) システム運用管理
システム運用管理
システムが運用要件を満たしているかどうかを定期的に評価することは重要である。様々な視点から,管理項目が設定され,例として次表のようなものがある。
| 指標 | 内容 |
|---|---|
| 機能性評価指標 | 要求機能の実現度 |
| 使用性評価指標 | 特定の利用の実現度 |
| 性能指標 | 応答時間,処理時間 |
| 資源の利用状況に関する指標 | 資源の利用状況 |
| 信頼性評価指標 | システム故障の頻度,障害件数,回復時間,稼働率 |
その他,安全性とセキュリティ,運用者の作業負担,利用者のシステム使用性なども評価項目として考えられる。
運用の資源管理(要員などの人的資源及びハードウェア,ソフトウェア,データ,ネットワークなどインフラストラクチャの技術的資源)
仮想環境の運用管理
ジョブの管理
データ管理
データ管理者(DA)とデータベース管理者(DBA)は,データベースの管理を専門的に扱う職種である。
- データ管理者(DA : Data Administrator)
- 業務の実世界から概念設計,システム化の範囲で論理設計などデータそのものの管理を行う。
- データベース管理者(DBA : DataBase Administrator)
- DA が設計した論理データモデルから物理設計を行い,データベースを構築したり,構築後のデータベースの運用設計および運用保守などのデータベースの管理を行う。
利用者の管理
コールドスタート
コールドスタートとは,当該システムを構成する機器の電源を完全に切って,ハードウェアが初期化された状態から再起動することである。イニシャルプログラムロードとも呼ばれる。
一般にコールドスタートは,記憶装置や OS の完全な初期化作業を行なうため,再起動にかかる時間はウォームスタートに比べて長くなる。ただし,コールドスタートをした場合,すべての機器にいったんリセットがかかるため,初期状態にリフレッシュされ,起動中のプロセスやメモリに残った不用なデータ,ノイズが取り除かれるというメリットがある。また,障害対応においてシステムにおける重要な項目の設定を変更する場合に,コールドスタートをしないと変更が反映されないことがある点にも留意しなければならない。
ウォームスタート
ウォームスタートとは,システム機器の電源を切らず,入力された情報が初期化されない状態で再起動を行うことである。システムが障害によって停止したとき,システムの再立上げの過程で,システム停止時に処理中であったジョブのうち,処理の続行が可能なものは処理を再開させ,入出力キューに残っているものは,そのまま処理の対象とする。
(2) 運用オペレーション
運用オペレーション
日々の運用をルール化,手順化して実施することである。ルール化,手順化する内容としては,次表のようなものがある。
| オペレーション | 内容 |
|---|---|
| ジョブスケジューリング | 日常的に行う作業(ジョブ)をスケジュール化する。自動実行できるようにすることで,管理者の負担軽減や人為的な作業ミスをなくすことができる。 |
| バックアップ | システムの故障に備えて定期的なバックアップを行う。 |
| システム監視 | システムの稼働状況やセキュリティの監視を行う。「監視ツール」や「診断ツール」などの運用支援ツールが使われる。 |
スケジュール設計
ジョブスケジューリング
演習問題
"24 時間 365 日" の有人オペレーションサービスを提供する。シフト勤務の条件が次のとき,オペレータは最少で何人必要か。
- 1 日に 3 シフトの交代勤務とする。
- 各シフトで勤務するオペレータは 2 人以上である。
- 各オペレータの勤務回数は 7 日間当たり 5 回以内とする。
- 8
- 9
- 10
- 16
正解は,2. である。
条件よりオペレータの人数は次式以上でなければならない。
バックアップ
- フルバックアップ方式
- 毎回データ全体のバックアップを行う方式。復旧時間は短くなるが,バックアップに要する時間は長い。
- 差分バックアップ方式
- 定期的にフルバックアップを行い,次のフルバックアップまでの期間は,フルバックアップ以降に変更のあったファイル(差分)だけを記録していく方式。バックアップ時間は短くて済むが,復旧は ① フルバックアップの適用 → ② 差分バックアップを適用という流れになるのでフルバックアップ方式と比較して作業時間がかかる。
システムの監視と操作
Web システムにおいて,ロードバランサ(負荷分散装置)が定期的に行っているアプリケーションレベルの稼働監視では,Web サーバの特定の URL にアクセスし,その結果に含まれる文字列が想定値と一致するかどうかを確認している。
アウトプットの管理
ジョブの復旧と再実行
運用支援ツール(監視ツール,診断ツール)
業務運用マニュアル
(3) サービスデスク
サービスデスク
サービスデスクは,ITIL が定義する機能の一つであり,インシデントの連絡の受付,対応及び解決に向けた活動を行う。サービスデスクの SLA の例を下表に示す。
| サービスレベル項目 | サービスレベル目標 | |
|---|---|---|
| サービス提供時間 | サービス提供日 | 月曜日から金曜日まで。ただし,祝日及び年末年始(12 月 29 日 ~ 1 月 3 日)を除く。 |
| サービス提供時間帯 | 9 時から 17 時まで。ただし,12 ~ 13 時を除く。 | |
| 回答時間1) | 15 分以内(95 %)2) | |
- 注1)サービス要求を受け付けて対応を開始してから最終的な解答を修了するまでの経過時間である。ただし,サービス提供時間帯以外は経過時間として計算しない。
- 注2)1 日のサービス要求件数の 95 % 以上のサービス要求は,経過時間が 15 分以内であることを表す。
サービスデスクを含む,サービスサポートの概念図を以下に示す。

SPOC (Single Point Of Contact)
SPOC とは,利用者からの問い合わせに対応する単一窓口のことで「Single Point of Contact」の略である。利用者からの問い合わせを一元管理することで,対応業務の効率化及び品質向上を目的として設置される。
コールセンタ
CTI(Computer Telephony Integration)
コンピュータと電話システムを連携・統合したもの。
FAQ (Frequently Asked Questions)
「よくある質問とその答え」をまとめたドキュメントを指す。FAQ を作成し公開することで,利用者が既知の問題を自分で解決できるようになるため,利用者満足度の向上や利用者対応業務の効率化などの効果が望める。
応対マニュアル
知識ベース
一次サポート
二次サポート及び三次サポート
サービスデスク組織の構造(ローカルサービスデスク,バーチャルサービスデスク,中央サービスデスク,フォロー・ザ・サン)
サービスデスクとは顧客からの問合せの窓口のことで,「ヘルプデスク」とも呼ばれている。サービスデスク組織の構造には,次表のような種類がある。
| 組織の構造 | 内容 |
|---|---|
| ローカルサービスデスク | サービスデスクを利用者の近くに配置することによって,言語や文化の異なる利用者への対応,専用要員による VIP 対応などができる。 |
| 中央サービスデスク | サービスデスクを 1 拠点または少数の場所に集中することによって,サービス要員を効率的に配置したり,大量のコールに対応したりすることができる。 |
| バーチャルサービスデスク | サービス要員は複数の地域や部門に分散していても,通信技術を利用して単一のサービスデスクであるかのようにサービスを提供することができる。 |
| フォロー・ザ・サン | 2 つ以上の異なる(大陸の)拠点に配置され,中央での統括管理によって 24 時間 365 日のサービスを提供するサービスデスク。 |
AI の活用(チャットボットなど)
利用者が質問のキーワードを入力すると,想定される質問とその回答を返す。利用者が期待する回答が得られない場合には,キーワードを追加させるなど対話的な対応をする。
ファシリティマネジメント
- ファシリティマネジメントの目的,考え方,施設や設備の管理,維持保全における留意事項を修得し,適用する。
(1) ファシリティマネジメント
「ファシリティ」とは,"設備" や "施設" を意味する。情報システムを構成するサーバやネットワークは,決められた施設内に設置して運用が行われている。ファシリティマネジメントは,設備や施設をはじめとして,情報システムの維持保全を行う一連の活動のことである。
① ファシリティマネジメントの目的と考え方
ファシリティマネジメント
IT サービスを提供するためには,その前提として,その IT サービスを運用するための施設・設備が,健全な状態で維持管理されていることが必要になる。
② 施設管理・設備管理
施設管理
システムを保有する施設や設備への障害となる内容とその対策の例として,次表のようなことが挙げられる。
| 障害 | 内容 |
|---|---|
| 火災 | 電子機器は水に弱いため,水を使用しないハロゲン化物や二酸化炭素を用いた消火設備を備えて対応する。 |
| 地震 | 免震構造を持つ耐震構造により,震動から機器を守る |
| 落雷 停電 瞬断 |
|
| 人的脅威 |
|
建物管理(免震装置,アレスタなどのサージ防護デバイス,防災防犯設備,安全管理関連知識ほか)
地震による被害からコンピュータ機器を守るため,フリーアクセス床には耐震性能の高いものや免振構造になっているものを採用し,機器やラックの転倒を防止するための必要な固縛を行うとともに,高所には重い機器を設置しないようにする。また,サーバ・ラックの下に置く機器用免振装置なども,機器の重要度に応じて導入する。
アレスタは避雷器ともいい,雷サージによって発生する過電圧を接地面に逃がすことによって,電気設備や機器が絶縁破壊するのを防止する機器である。アレスタは雷サージのような異常な過電圧に対してのみ動作し,動作後は回路を元の正常な状態に戻す自己回復の機能を持っている。
消火設備(泡消火設備,ハロゲン化物消火設備,不活性ガス消火設備など)
コンピュータ室の消火には水が利用できないため,ハロゲン化物(ハロン)や二酸化炭素を用いた消火設備を利用することになる。
- ハロン化物消火設備
- 消火薬剤にハロンガスを使用した消火設備を,ハロン化物消火設備と呼ぶ。酸素濃度を低下させ,燃焼の連鎖反応を抑制することで消火する。なお,ハロンガスはオゾン層を破壊するおそれがあるため,現在は生産が中止されているが,消火剤として有用であることから,使用は認められている。
- 二酸化炭素消火設備
- 二酸化炭素を放出し,酸素濃度を下げることで消火を行う設備を,二酸化炭素消火設備という。複雑な形状の電子機器の消火に対応できる。ただし,高濃度の二酸化炭素は人体に対して強い毒性があり,場合によっては死に至るため,使用前には室内の人を避難させるなど細心の注意が必要である。
電気設備(UPS,自家発電設備ほか)
UPS (Uninterruptible Power Supply) は,落雷などによる突発的な停電発生したときに自家発電装置が電源を供給し始めるまでの間,サーバに電源を供給する役目をもつ機器である。機器内部に電気を蓄えていて,電源の瞬断時にシステムを安全に終了する時間を与えてくれたり,自家発電装置による電源供給までの間,つなぎの役目を果たしたりする。
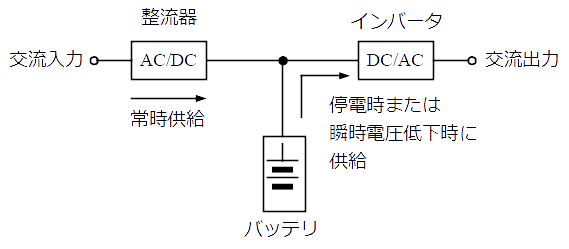
電力会社からの電力供給が長時間停止する場合を想定し,自家発電設備を設置する場合がある。
空調設備(空調機器,コールドアイル,ホットアイルほか)
冷房負荷は,室内の温度・湿度を一定に保つために,空気から取り除くべき熱量をいう。太陽熱,室外から侵入する空気内の熱,機器・照明の熱,室内外の温度差による窓や壁からの伝熱などがある。
| 冷房負荷の種類 | 軽減策 |
|---|---|
| 外気負荷 | 隙間風や換気による影響を少なくする。 |
| 室内負荷 | 使用を終えたら,その都度 PC の電源を切る。 |
| 伝熱負荷 | 屋根や壁面の断熱をおろそかにしない。 |
| 日射負荷 | 日光が当たる南に面したガラス窓をむやみに大きなものにしない。 |
サーバ・ラックの列で区切られたサーバ室内のうち,サーバの廃熱だけを集めた空間をホットアイル (hot aisle),空調機が送り出してサーバが吸引する冷気を集めた空間をコールドアイル (cold aisle) という。ホットアイルとコールドアイルを明確に分けることで,サーバ室内の冷却効率が向上し,空調機が消費する電力を削減できる。
なお,ラック列間の通路を壁や屋根で区画し,IT 機器への給気(低温)と IT 機器からの排気(高温)を物理的に分離して効率的な空調環境を実現する気流制御技術を,アイルキャッピングという。
クールピットは,データセンターなどで用いられている環境に配慮した空調システムであり,夏季は外気よりも低温になる地中と外気との温度差を熱交換に利用する。
床下送風方式(床下空調方式)の場合,床下からの冷たい送風によって機器にたまった暖気が天井側に上昇する流れを加速させ,効率良く機器を冷却させるという特徴がある。
通信設備(MDF,IDF ほか)
MDF(Main Distributing Frame : 主配線盤)は,建物外部から数多くの電話回線や通信ケーブル(WAN など)を引き込む場合に設置され,それらを集約するための配線盤である。MDF を介して各階の IDF に配線される場合が多い。
IDF(Intermediate Distributing Frame : 中間配線盤)は,ビルの各階などに設置され,主配線盤(MDF)と末端(アウトレット)とを中継する配線盤である。
PBX (Private Branch eXchange) は,ビル構内の電話機と外部の公衆電話網との接続や,ビル内の内線電話同士の接続時に,中継の役割を果たす交換機である。近年は IP 電話が普及しており,IP ネットワーク上の IP 電話網と外部の公衆電話網とを接続する IP-BPX (IP Private Branch eXchange) が設置され,ユニファイドメッセージ(電話やコンピュータなどのメッセージを統合管理すること)が利用されるなど,電話とコンピュータの親和性が高まっている。

データファシリティスタンダード(ティア(Tier)基準)
③ 施設・設備の維持保全
施設・設備の維持保全
④ 環境側面
環境側面
グリーン IT
環境側面では,地球環境に配慮した IT 製品や IT 基盤,環境保護や資源の有効活用につながる IT 利用を推進することが大切である。この思想のことをグリーン IT という。
データセンタ総合エネルギー効率指標(GEC,PUE,ITEE,ITEU ほか)
グリーン IT の一環として,データセンタの省エネ化が急務となっている。日本ではグリーン IT 推進協議会(GIPC : Green IT Promotion Council)や総務省が,データセンタの総合エネルギー効率指標(DPPE : Datacenter Performance per Energy)を用いたデータセンタのエネルギー効率の総合的な評価の普及に努めている。DPPE の 4 つの指標 GEC,PEU,ITEE,ITEU は,次のとおりである。
GEC(Green Energy Coefficient : グリーンエネルギー効率)とは,太陽光発電や風力発電などのグリーンエネルギーがデータセンタでどれだけ使われているかを測る指標であり,次式で表される。
PUE(Power Usage Effectiveness : 付帯設備電力効率)とは,データセンタの消費電力効率を測る指標であり,空調設備や電源設備などの付帯設備を含め,データセンタ施設が IT 機器の何倍の消費電力で稼働しているかをみるものである。
ITEE(IT Equipment Energy Efficiency : IT 機器電力効率)とは,IT 機器の省エネルギー性能を示す指標で,IT 機器のカタログに掲載された省エネ効率の値にあたる。IT 機器を調達する際の指標となり,次式で表される。
ITEU(IT Equipment Utilization : IT 機器利用効率)とは,IT 機器の性能をどれだけ有効に使っているかを示す指標で,次式で表される。
ZEB(net Zero Energy Building)
LEED(Leadership in Energy & Environmental Design)認証
GHG プロトコル
応用情報技術者 午後 問題のテーマ
平成21年度 春期以降の応用情報技術者 午後 問題のテーマを示す。
- 令和5年度 秋期 問10 サービスレベル
- 令和5年度 春期 問10 クラウドサービスのサービス可用性管理
- 令和4年度 秋期 問10 サービス変更の計画
- 令和4年度 春期 問10 サービスマネジメントにおけるインシデント管理と問題管理
- 令和3年度 秋期 問10 変更管理
- 令和3年度 春期 問10 SaaS を使った営業支援サービス
- 令和2年度 問10 サービスの予算業務及び会計業務
- 令和元年度 秋期 問10 IT サービスマネジメントの改善
- 平成31年度 春期 問10 サービス運用のアウトソーシング
- 平成30年度 秋期 問10 キャパシティ管理
- 平成30年度 春期 問10 データセンタで行うシステム運用
- 平成29年度 秋期 問10 サービスデスク
- 平成29年度 春期 問10 サービスマネジメントにおけるマネジメントプロセスとサービスデスクの運用
- 平成28年度 秋期 問10 販売管理サービスの変更
- 平成28年度 春期 問10 キャパシティ管理
- 平成27年度 秋期 問10 サーバ仮想環境における運用管理
- 平成27年度 春期 問10 情報資産の管理
- 平成26年度 秋期 問10 販売管理システムの問題管理
- 平成26年度 春期 問10 サービス継続及び可用性管理
- 平成25年度 秋期 問10 情報システムのサービスレベルの設定
- 平成25年度 春期 問11 業務で利用する PC 及びソフトウェアの管理
- 平成24年度 秋期 問11 情報システムの変更管理
- 平成24年度 春期 問11 IT サービス継続マネジメント
- 平成23年度 秋期 問11 仮想環境の運用管理
- 平成23年度 春期 問11 システムの変更管理
- 平成22年度 秋期 問11 バックアップ
- 平成22年度 春期 問11 サービスサポート業務のインシデント管理における作業プロセスの改善
- 平成21年度 秋期 問11 IT サービスにおけるサービスサポート
- 平成21年度 春期 問11 SLA (Service Level Agreement)
本稿の参考文献
- JIS Q 9001 : 2015「品質マネジメントシステム−要求事項」"Quality management systems-Requirements"
- JIS Q 20000-1 : 2020「情報技術−サービスマネジメント− 第1部:サービスマネジメントシステム要求事項」"Information technology-Service management-Part 1: Service management system requirements"
- JIS Q 20000-2 : 2013「情報技術-サービスマネジメント-第2部:サービスマネジメントシステムの適用の手引」"Information technology -Service management- Part 2 : Guidance on the application of service management systems"
- 日本データセンター協会,「データセンターファシリティスタンダード」
- 野村総合研究所システムコンサルティング事業本部,「ITIL 入門 IT サービスマネジメントの仕組みと活用」,株式会社 ソーテック社,2008年1月31日
- 最上 千佳子 著,「ITIL はじめの一歩 スッキリわかる ITIL の基本と業務改善の仕組み」,株式会社 翔泳社,2019年3月11日
![[商品価格に関しましては,リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/1ee2a380.5327b49b.1ee2a381.6d6071b3/?me_id=1213310&item_id=19468134&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8884%2F9784798158884.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては,リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
